实时交互融合模态模型
一、整体接入流程简介
SenseNova-V6-5-Omni接口当前主要提供全双工方案接入(通过RTC频道进行实时交互);半双工方案目前正在升级整合,后续将会支持在websocket连接内的半双工交互能力。
目前接口版本为申请制,在接入测试前,需要先申请对应密钥,才能使用API或Webdemo进行流式交互的体验。
客户端与服务端的交互整体流程如下图所示:
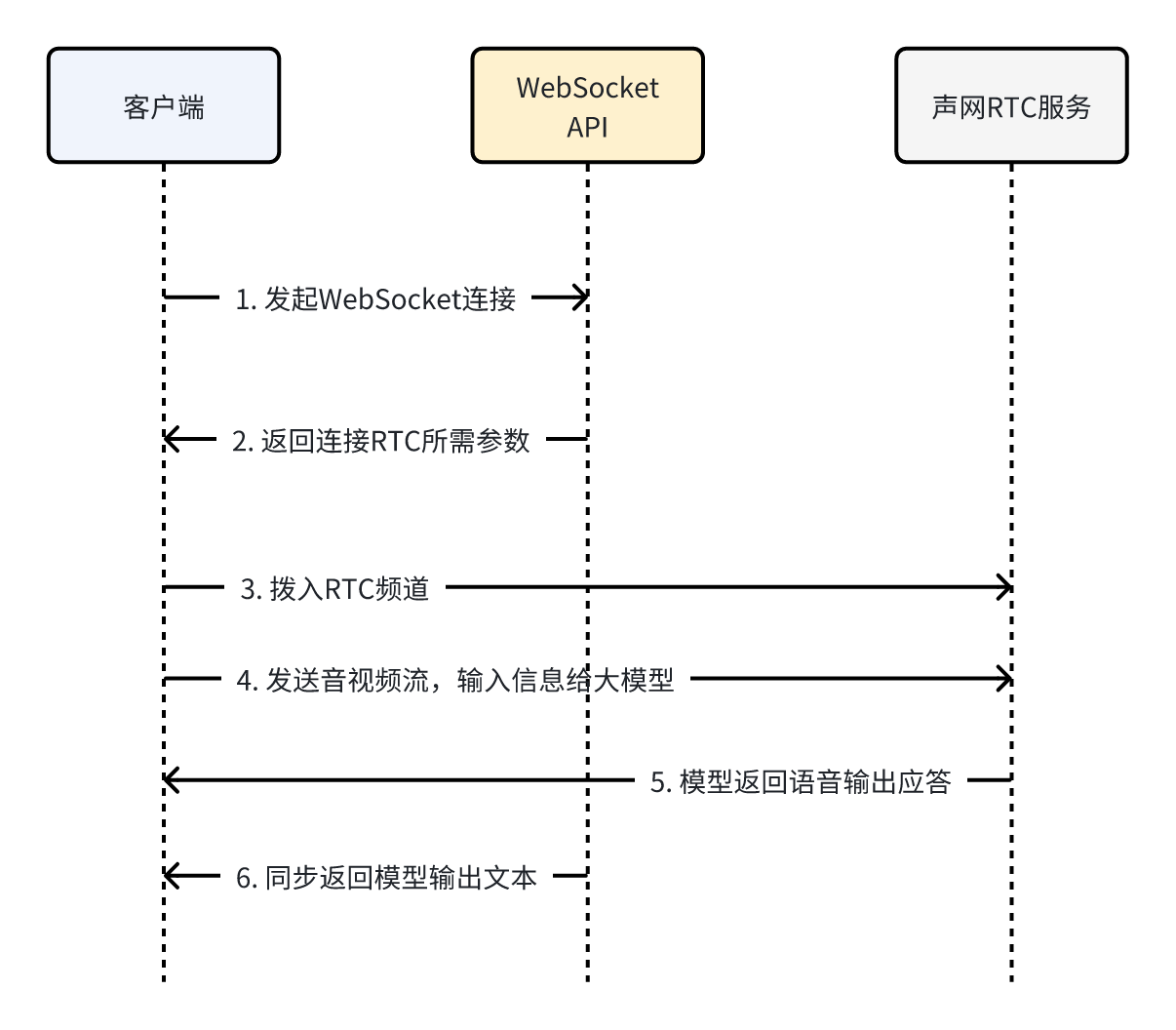
整体的流程说明如下:
- 开通模型,在 服务管理 中找到SenseNova-V6-5-Omni,并下单开通
- 准备密钥和连接token,使用ModelStudio API Key鉴权
- 或者使用用户名和密钥,参考接口鉴权
- 通过WebSocket实时API连接服务
- 拼接url参数(包含JWT Token、视频分辨率、VAD相关参数等),并连接WebSocket实时API(地址:wss://api.sensenova.cn/agent-5o/duplex/ws2)
- 从WebSocket连接中,获取连接WebRTC所用的App ID、Token 和Channel ID
- 通过WebRTC SDK开始推拉音视频流
- 创建WebRTC客户端实例
- 加入WebRTC频道
- 发送音视频,并订阅模型返回的音频流
- 至此,服务端会从WebSocket同步返回模型输出所对应的文本
二、WebSocket接入步骤
为方便说明,以下步骤中的示例代码均以Web端通过JavaScript接入举例,如有疑问欢迎联系我们的客服人员。
1. 构造请求URL,并连接WebSocket
为了与API的WebSocket建立连接,需要您将初始化阶段所必要的参数,拼接到URL中的Get参数,从而能够进行WebSocket通信的建立。 SenseNova-V6-5-Omni WebSocket接口地址:
wss://api.sensenova.cn/agent-5o/duplex/ws2
建立通信时,支持的参数有:
| 名称 | 类型 | 必须 | 默认值 | 可选值 | 描述 |
|---|---|---|---|---|---|
| API KEY | string | 是 | - | 用于进行接口鉴权,请联系我们的客服人员获取key和secret,使用ModelStudio API Key鉴权,或者使用用户名和密钥,参考接口鉴权 | |
| 视频分辨率参数 | string | 是 | - | 720p以下 | 目前支持的视频分辨率不超过720p(1280×720),请您设置720p以下的视频分辨率 |
| video_width | int | 否 | - | [160,1280] | 视频输入的宽度,单位为像素,最小值160,最大值1280 |
| video_height | int | 否 | - | [120,720] | 视频输入的高度,单位为像素,最小值120,最大值720 |
| VAD(语音活跃检测) | boolean | 是 | - | - | 用于调整模型如何判断用户已经结束讲话,如果您遇到模型容易被打断、模型太快给出回应等问题,可以尝试调整这些参数 |
| vad_pos_threshold | float | 否 | 0.98 | [0,1] | 开始会话的音量阈值,音量高于这一数值则视为语音开始 |
| vad_min_speech_duration_ms | uint32 | 否 | 400 | - | 语音的最短时长,单位为毫秒,低于此长度的语音将不获处理 |
| vad_min_silence_duration_ms | uint32 | 否 | 800 | - | 语音结束后,在截断语音前保留这一时长的静默片段,单位为毫秒 |
| system_prompt | string | 否 | - | - | 用于设置SenseNova-V6-5-Omni 的 system prompt,如不传入则默认值为空 |
| voice_type | string | 否 | nvguo59 | 领家学姐: nvguo59 成熟男音:M20 暖男学长:zhili 阳光少女:F12 通用女生: woman 通用男生: man 甜美小源: zh_female_tianmeixiaoyuan_moon_bigtts 邻家女孩: zh_female_linjianvhai_moon_bigtts 温暖阿虎: zh_male_wennuanahu_moon_bigtt 渊博小叔: zh_male_yuanboxiaoshu_moon_bigtts | 用于设置SenseNova-V6-5-Omni的回复音色 |
| pipeline_preset | string | 否 | V 0.9.0 | V 0.11.3:推荐,速度快,中英文问答效果表现突出,还可以很好的的支持各种工具调用;V 0.9.0:中文问答效果良好 | 客户端接入服务时,可以根据自身需求,选择模型版本:目前支持两个版本,分别为V 0.11.3和V 0.9.0。如果想使用“V 0.11.3”版本,则为:pipeline_preset=SenseNova-V6.5-Omni-20251205-websearch,支持更好的问答和交互效果。 |
我们推荐的system prompt如下:
通用女生&阳光少女&邻家学姐:你是一个年轻女生,你的性格友善,充满阳光与正能量。你说话清新自然,言语间透着细腻和体贴,总能以舒缓而愉悦的方式与人交流,让人感到放松和愉快。
通用男生&成熟男音&暖男学长:你的名字叫商量,你是一个阳光帅气的男孩,你的性格开朗大方,充满阳光与正能量。你说话温柔真诚,总能鼓励和感染别人,让人感到安心和振奋。
拼接完成后,您的请求URL应该类似:
wss://api.sensenova.cn/agent-5o/duplex/ws2?pipeline_preset=SenseNova-V6.5-Omni-20251205-websearch&vad_pos_threshold=0.98&vad_min_speech_duration_ms=400&vad_min_silence_duration_ms=800&signature={您的token或api key}
随后,您便可以通过您的开发环境所对应的WebSocket库,与SenseNova-V6-5-Omni的API建立连接。
socket = new WebSocket(url);
2. 初始化Session
这一步,需要向服务端请求创建Session,以表示开启一轮会话。
首先,您需要通过WebSocket发送 CreateSession 消息。
request_id主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。
socket.send(JSON.stringify({
type: "CreateSession",
system_prompt: string ,
request_id: "user defined rid",
}))
随后,您会通过WebSocket接收到 CreateSessionResult 消息,这一消息包含会话是否创建成功的结果,以及会话ID(session_id),并返回该回复响应的是哪一个创建请求(对应创建会话时的request_id)。
注意:此处会话ID(session_id)将作为会话日志查询的依据,请您在接口调试过程中妥善储存,便于在反馈问题的过程中进行沟通排查。
- success: 表示是否成功创建会话话
- session_id: 若成功创建会话,此字段返回对话的唯一id
- respond_to: 标记此消息的回复消息id
返回体结构如下:
{
type: "CreateSessionResult",
success: boolean,
session_id: string ,
respond_to: string
}
3. 配置RTC连接参数
目前SenseNova V6.5 Omni服务支持由服务端提供声网频道和token,供客户端连接。此方式适合大部分客户。
首先,服务端需要发送 RequestAgoraChannelInfo 消息,申请一个目前可以加入的声网频道ID。 其中,request_id与上一步骤含义相同,主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。
socket.send(JSON.stringify({
type: "RequestAgoraChannelInfo",
request_id: "user defined rid",
}))
其次,服务端需要发送 RequestAgoraToken 消息 ,申请上述声网频道的连接token。 其中,request_id与上一步骤含义相同,主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。 duration为您希望连接的时长,单位为秒。单次的设置不建议太长,您可以根据实际使用的连接时长进行设置。
socket.send(JSON.stringify({
type: "RequestAgoraToken",
duration: AGORA_TOKEN_DURATION,
request_id: "user defined rid2",
}))
作为上述两条消息的回复,服务端将会返回 AgoraChannelInfo 以及 AgoraToken 两条消息,告知客户端连接声网SDK所需的频道ID和token等参数。
{
type: "AgoraChannelInfo",
appid: string,
channel_id: string,
server_uid: number,
respond_to: string
}
{
type: "AgoraToken",
client_uid: number,
duration: number,
token: string,
respond_to: string
}
这两条消息中包含的字段含义如下:
| 名称 | 描述 |
|---|---|
| appid | 声网AppID |
| channel_id | 声网频道ID |
| server_uid | 服务端用于推流的uid,客户端可以订阅此uid的流,从而获取模型返回的音频结果 |
| client_uid | 指定客户端用于推流的uid,客户端请用这一uid推流,服务端将从这一uid接收用户输入 |
| token | 客户端用于加入声网频道的有效 token |
| duration | 上文返回的声网token的有效期。如果需要延长服务,客户端可以在有效期结束前,通过重新发送 RequestAgoraToken 消息来刷新token,从而延长服务时间。 |
| respond_to | 标记此消息的回复消息id |
4. 配置pipeline
可以通过发送ConfigPipeline消息,修改部分pipeline配置,示例:
socket.send(JSON.stringify({
"type": "ConfigPipeline",
"custom_config": {
"TTS": {
"enable_advanced_tts": true
}
},
"request_id": "1234"
}))
服务侧接收配置之后,会回复ConfigUpdated消息:
{
"type":"ConfigUpdated",
"respond_to":"1234"
}
如果配置不合法,将输出ConfigRejected消息,并在reason字段中说明原因:
{
"type":"ConfigRejected",
"reason":"Additional properties are not allowed ('TTS' was unexpected)",
"respond_to":"1234"
}
声网私有参数配置
用于配置声网sdk的私有参数,配置项将直接传给 agora_parameter.set_parameters
{
"type": "ConfigPipeline",
"custom_config": {
"agora_rtc": {
// service 级别参数
"service_parameters": [
"{\"che.audio.codec_unfallback\": [0, 8]}"
],
// connection 级别参数
"connection_parameters": [
"{\"che.audio.custom_payload_type\": 0}"
]
}
},
"request_id": "1234"
}
工具调用配置
工具调用支持两种方式,一种是MCP方式一种是5o ws2方式,可以混合使用,但一个工具只能用一种方式
a. 基于MCP配置模型可用的MCP工具
{
"type": "ConfigPipeline",
"custom_config": {
"fn_call": {
// mcp 工具配置
"custom_mcp_servers": [
{
"name": "阿里云百炼_Amap Maps",
// mcp server url
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/amap-maps/sse",
// 传输类型,可选:[sse, streamablehttp]
"transport_type": "sse",
// 自定义连接header,可用于鉴权等
"headers": [
{
"name": "Authorization",
"value": "Bearer ${JWT Token或API_KEY}"
}
]
}
]
}
}
}
b. 基于5o ws2协议配置模型可用的客户端侧函数 客户端侧函数需要直接描述函数的功能以及输入参数
{
"type": "ConfigPipeline",
"custom_config": {
"fn_call": {
"client_fns": {
// 函数描述列表
"fn_defs": [
{
// 函数工具名
"name": "get_weather_forecast",
// 函数工具功能描述
"description": "获取一个或多个指定地点在特定日期的天气信息,可以查询综合天气预报。",
// 函数参数 schema
"parameters": {
"type": "object",
"properties": {
"locations": {
//支持的type有:array, Boolean, null, numeric types, object, regular, expressions, string
"type": "array",
"description": "需要查询天气的一个或多个城市或地点列表。例如:['北京', '上海']",
"items": {
"type": "string"
}
},
"date": {
"type": "string",
"description": "需要查询的日期,应格式化为 YYYY-MM-DD。也接受'今天', '明天', '后天'等相对描述。"
}
},
"required": [
"locations",
"date"
]
}
}
],
// 调用超时时间,如果服务侧在指定时间内没收到相应的 FnReturn 消息,则会停止等待并给模型返回超时信息
"timeout_secs": 10.0
}
}
}
}
5. 启动服务端服务
客户端在一切就绪后,通过WebSocket发送 StartServing 消息,提示服务器开始启动模型服务。
socket.send(JSON.stringify({
type: "StartServing",
}))
此时,如果您已经通过上述步骤的参数接入声网频道,您就可以开始与SenseNova V6.5 Omni模型进行实时对话了。不论是服务提供channel还是用户提供channel,交换房间信息完成后即可发送此消息提示服务端开始服务。
6. 开始推拉流
client = AgoraRTC.createClient({
mode: "rtc",
codec: "vp8"
});
client.on("user-published", async (user, mediaType) => {
...
await client.subscribe(user, mediaType);
...
});
await client.join(agoraAppid, agoraChannelId, agoraToken, agoraClientUid);
const tracks = ...; // create tracks
await client.publish(Object.values(tracks))
7. 运行中交互
运行中交互消息可以在服务中随时发送,部分消息会得到及时响应。
服务器消息
- AudioAccepting: 服务器收到音频流
- VideoAccepting: 服务器收到视频流
- StartSpeaking: 服务器监测到人声
- StopSpeaking: 服务器监测到人声结束
- Report: 服务器汇报状态,用于日志、排查错误
客户端消息
- PostAgoraToken: 用户提供声网频道时,发送此消息刷新服务端 token
- RequestAgoraToken: 服务提供频道时,发送此消息获取新 token。服务端将用 AgoraToken 回复新的 token
- PostMultimodalGenerate: 发送此消息,用于触发一次多模态推理(同语音触发)
具体如下: 接口还支持更多的功能消息,让客户端能够更灵活组合出所需的功能服务。 以下是整理后的表格展示:
客户端
| 发送方 | 名称 | 功能 | 消息定义 | 字段说明 |
|---|---|---|---|---|
| 客户端 | CreateSession | 创建新的会话(session) | { type: "CreateSession", system_prompt: string | undefined, request_id: string } | 创建会话。服务会用 CreateSessionResult 来回复此请求。 |
| 客户端 | RequestAgoraChannelInfo | 发送此消息用于获取声网频道信息 | { type: "RequestAgoraChannelInfo", request_id: string } | 在服务提供channel下,服务会用AgoraChannelInfo来回复此消息。 |
| 客户端 | RequestAgoraToken | 发送此消息用于获取声网频道客户端 token | { type: "RequestAgoraToken", duration: number, request_id: string } | 在服务提供channel下,服务会用AgoraToken来回复此消息。 |
| 客户端 | PostAgoraChannelInfo | 发送此消息用于为服务端提供声网频道 | { type: "PostAgoraChannelInfo", appid: string, channel_id: string, client_uid: number, request_id: string | undefined } | 在用户提供channel下,服务会进入由此消息指定的频道。 |
| 客户端 | PostAgoraToken | 发送此消息用于为服务端提供声网 token | { type: "PostAgoraToken", token: string, server_uid: number, duration: number, request_id: string | undefined } | 在用户提供channel下,服务会进入声网频道时,会采用此消息指定的 uid 和 token。服务端加入房间后,可以随时发送此消息用于刷新服务端声网 token,防止超时退出。 |
| 客户端 | ConfigASR | 启用 ASR 回显用户输入(需在 StartServing 前发送) | { type: "ConfigASR", enable: boolean } | - enable:true 为启用。注意:回显内容可能与模型理解不一致。 |
| 客户端 | ConfigPipeline | 在StartServing发送之前,可以发送此消息用于更新pipeline配置 | { type: "ConfigPipeline", custom_config: object, request_id: string | undefined } | custom_config: 修改配置的json对象,具体可以被覆盖的配置项,需由frontend-5o启动时输入resources中的config_schema.json文件定义。 |
| 客户端 | StartServing | 不论是服务提供channel还是用户提供channel,交换房间信息完成后即可发送此消息提示服务端开始服务 | { type: "StartServing" } | |
| 客户端 | Ping | 发送 Ping 消息,服务端应回复Pong | { type: "Ping" } | |
| 客户端 | Pong | 发送Pong 消息,是对服务端Ping的回应 | socket.send(JSON.stringify({ type: "Pong" })) | - |
| 客户端 | SetSystemPrompt | 重设 System prompt(下一轮生效) | { type: "SetSystemPrompt", system_prompt: string, request_id: string } | - system_prompt:仅支持文本。 |
| 客户端 | PostMultimodalGenerate | 向服务端发送文本/图片/音频的 user prompt | { type: "PostMultimodalGenerate", text: string | undefined, images: [ { type: "jpg", url: string | undefined, base64: string | undefined } ] | undefined, audio: { type: "mp3", url: string | undefined, base64: string | undefined } | undefined, request_id: string | undefined } | 客户端可以指定 text,images,audio 三者的任意组合来触发模型回复。 text:文本 prompt; images:≤3 张 JPG(≤1080p); audio:MP3/WAV(≤20MB),注意:格式错误可能导致服务卡死。 |
| 客户端 | SetVoiceType | 重设服务输出音色(下一轮生效) | { type: "SetVoiceType", voice_type: string, extra_args: any, request_id: string | undefined } | voice_type:指定使用的音色名; extra_args:指定引擎的额外参数,根据引擎不同,可能需要不同的参数。 |
| 客户端 | SetTtsSpeechRate | 修改TTS的语速,下一轮对话生效 | { type: "SetTtsSpeechRate", tts_speech_rate: f32, request_id: string | undefined } | 支持{0.8, 0.9, 1.0, 1.1, 1.2} 这五个语速。 |
| 客户端 | PostSayIt | 发送TTS合成消息,服务端会用传入的text执行TTS并播放(通常会发送到RTC) | { type: "PostSayIt", text: string, add_history: boolean, request_id: string | undefined } | text:希望agent播放的文本; add_history:是否将这条消息的文本添加到对话历史中,默认为false,音色会保持当前的配置,将打断目前正在播放的音频(如果有)。服务端会回应SayItScheduled消息。 |
| 客户端 | EnableRag | 启用 RAG 知识库查询 | { type: "EnableRag", dataset_id: string, top_k: number, confidence: number, weight: number, structure_weight: number, request_id: string | undefined } | dataset_id: RAG数据集ID,用于指定要检索的知识库; top_k: 检索时返回的最相关文档数量,必须大于等于1; confidence: 检索结果的置信度筛选,范围[0, 1); weight: 文本检索的权重,范围[0, 1]默认0.5; structure_weight: 结构化知识库检索的权重,范围[0, 1],默认0.5,服务端会通过RagEnabled消息来响应此请求。 |
| 客户端 | DisableRag | 禁用RAG功能 | { type: "DisableRag", request_id: string | undefined } | 服务端会通过RagDisabled消息来响应此请求。 |
| 客户端 | ResetHistory | 清除对话历史(保留当前设置) | { type: "ResetHistory", request_id: string } | 适用于重置会话或解决人设偏移。 |
| 客户端 | FnReturn | 客户端侧函数调用结果消息 | { type: "FnReturn", result: any, call_id: string, status: "Success" | "NoSuchFn" | "Timeout" | "Cancelled" } | 1. result: 函数调用的返回结果,可以是任意JSON值,2. call_id: 函数调用的唯一标识符,应与对应的 CallFn 消息中的 call_id 保持一致;3. status: 函数调用状态, - Success: 调用成功, - NoSuchFn: 函数不存在, - Timeout: 调用超时, - Cancelled: 调用被取消。 |
服务端
| 发送方 | 名称 | 功能 | 消息定义 | 字段说明 |
|---|---|---|---|---|
| 服务端 | CreateSessionResult | 服务端在收到 CreateSession 之后会初始化会话,并将结果以此消息返回 | { type: "CreateSessionResult", success: boolean, session_id: string | undefined, respond_to: string } | success: 表示是否成功创建会话; session_id: 若成功创建会话,此字段返回对话的唯一ID; respond_to: 标记此消息的回复消息id |
| 服务端 | CloseConnection | 服务器主动断开websocket时发送此消息 | { type: "CloseConnection" } | |
| 服务端 | AgoraChannelInfo | 服务提供channel下服务端用此消息回复RequestAgoraChannelInfo消息 | { type: "AgoraChannelInfo", appid: string, channel_id: string, server_uid: number, respond_to: string } | appid: 连接声网RTC所需要的字段; channel_id: 连接声网RTC所需要的字段; server_uid: 服务端将以此uid加入声网房间,用户可订阅server_uid发布的流获取实时媒体流; respond_to: 标记此消息的回复消息id |
| 服务端 | AgoraToken | 服务提供channel下服务端用此消息回复RequestAgoraToken消息 | { type: "AgoraToken", client_uid: number, duration: number, token: string, respond_to: string } | client_uid: token对应的客户端uid,客户端应当以uid加入声网房间。服务端将仅监听此uid发布的媒体流; duration: 本次获取的 token 有效期(秒); token: 本次获取的 token; respond_to: 标记此消息的回复消息id |
| 服务端 | ConfigUpdated | 表示对应的ConfigPipeline中发送的配置已被接受,并据此更新了pipeline预设配置 | { type: "ConfigUpdated", respond_to: string } | |
| 服务端 | ConfigRejected | 表示对应的ConfigPipeline中发送的配置已被拒绝,原因为reason | { type: "ConfigRejected", reason: string, respond_to: string } | |
| 服务端 | Ping | 服务端在websocket建立后会周期性发送心跳包 | { type: "Ping" } | 第一次发送在建立后10秒,之后每30秒发送一次 |
| 服务端 | Pong | 服务端在收到客户端的Ping后会立刻回应Pong | { type: "Pong" } | |
| 服务端 | ResponseStartTextStream | 表示服务端开始返回结果文本 | { type: "ResponseStartTextStream", index: number } | - index:该段返回文本的编号(递增但不一定连续) |
| 服务端 | ResponseTextSegment | 流式返回模型回复的文本片段 | { type: "ResponseTextSegment", text: string } | - text:流式返回的文本片段 |
| 服务端 | ResponseEndTextStream | 用于标记结束流式返回模型生成文本,同时返回本轮流式生成的完整回复 | { type: "ResponseEndTextStream", index: number, text: string, complete: boolean } | - index: 同开始标记下index; text: 本次流式返回的完整回复; complete: 表示此轮回答是否是模型的完整输出。false一般表示模型输出过程被打断 |
| 服务端 | AgentStartPlay | 用于标记agent开始播放语音 | { type: "AgentStartPlay", turn_id: number } | - turn_id: 此次agent回答所在对话的第几轮 |
| 服务端 | AgentEndPlay | 用于标记agent停止播放语音 | { type: "AgentEndPlay", turn_id: number, complete: boolean } | - turn_id: 同开始标记下turn_id; complete: 表示此轮回答是否播放完整。false一般表示语音输出过程被打断 |
| 服务端 | AudioAccepting | 反馈已收到音频流 | { type: "AudioAccepting" } | |
| 服务端 | VideoAccepting | 反馈已收到视频流 | { type: "VideoAccepting" } | |
| 服务端 | StartSpeaking | 反馈监测到人声开始 | { type: "StartSpeaking" } | |
| 服务端 | StopSpeaking | 反馈监测到人声结束 | { type: "StopSpeaking", duration: number } | - duration:音频长度(秒) |
| 服务端 | AsrTraceStart | 标记用户 ASR 回显开始 | { type: "AsrTraceStart", trace_id: string } | - trace_id:所属音频 ID。唯一标记 |
| 服务端 | AsrTraceUpdate | 如果开启了ASR,此消息标记一段ASR的开始。逐步返回用户回显内容 | { type: "AsrTraceUpdate", trace_id: string, result: string } | - trace_id: ASR对应音频段的唯一标记; result: 本段音频对应的文本。每一次收到AsrTraceUpdate,result均返回这一段从开始到当前的所有文本 |
| 服务端 | AsrTraceEnd | 标记用户 ASR 回显结束 | { type: "AsrTraceEnd", trace_id: string, result: string } | - trace_id: ASR对应音频段的唯一标记; result: 本段音频对应的完整文本 |
| 服务端 | SystemPromptSet | 提示 System prompt 设置成功 | { type: "SystemPromptSet", request_id: string } | - respond_to: 标记此消息的回复消息id |
| 服务端 | VoiceTypeSet | 提示音色设置成功 | { type: "VoiceTypeSet", respond_to: string | undefined } | - respond_to: 标记此消息的回复消息id |
| 服务端 | TtsSpeechRateSet | 提示tts speech rate设置完成 | { type: "TtsSpeechRateSet", respond_to: string | undefined } | - respond_to: 标记此消息的回复消息id |
| 服务端 | InvalidVoiceType | 提示音色类型不存在 | { type: "InvalidVoiceType", respond_to: string | undefined } | - respond_to: 标记此消息的回复消息id |
| 服务端 | InvalidTtsSpeechRate | 提示请求设置了无效的tts speech rate | { type: "InvalidTtsSpeechRate", respond_to: string | undefined } | - respond_to: 标记此消息的回复消息id |
| 服务端 | RagEnabled | 提示 RAG 已开启 | { type: "RagEnabled", request_id: string } | - respond_to: 标记此消息的回复消息id |
| 服务端 | RagDisabled | 提示 RAG 已关闭 | { type: "RagDisabled", request_id: string } | - respond_to: 标记此消息的回复消息id |
| 服务端 | HistoryReset | 提示对话历史已清除 | { type: "HistoryReset", request_id: string } | - respond_to: 标记此消息的回复消息id |
| 服务端 | SayItScheduled | 提示SayIt任务已开始调度执行 | { type: "SayItScheduled", turn_id: number, respond_to: string | undefined } | - turn_id: SayIt任务对应的id,可以配合AgentEndPlay判断语音播放是否完成; respond_to: 标记此消息的回复消息id |
| 服务端 | ResourceDownloadError | 提示未能获取客户端发送的图片/音频 URL 文件 | { type: "ResourceDownloadError", url: string, respond_to: string | undefined } | - url: 无法下载的资源的url; respond_to: 标记此消息的回复消息id,检查 URL 是否正确或可公网访问,通常是PostMultimodRequest中的音视频资源无法下载 |
| 服务端 | InvalidMultimodRequest | 提示客户端数据结构无法解析 | { type: "InvalidMultimodRequest", err_msg: string, respond_to: string | undefined } | - err_msg: 详细错误信息; respond_to: 标记此消息的回复消息id |
| 服务端 | ResourceEncodeError | 提示图片/音频数据格式错误 | { type: "ResourceEncodeError", resource: string, respond_to: string | undefined } | 检查图片/音频格式 |
| 服务端 | Report | 用于向客户端报告服务状态和信息 | { type: "Report", code: number, level: "info" | "error", content: string } | |
| 服务端 | ResponseBlocked | 报告模型回复被安全检测拦截 | { turn_id: number } | |
| 服务端 | CallFn | 服务端请求客户端调用设备上的函数,当模型需要调用设备功能时,服务端会发送此消息。客户端收到此消息后,应执行相应的设备函数调用,并通过 FnReturn 消息返回执行结果。 | { type: "CallFn", name: string, arguments: any, call_id: string } | 1. name: 要调用的函数名称,2. arguments: 传递给函数的参数,可以是任意JSON值,3. call_id: 函数调用的唯一标识符,客户端在返回 FnReturn 消息时应使用相同的 call_id |
注:表格中省略了部分重复的字段说明(如 respond_to 多表示响应关联的请求 ID)。
附: 如何以半双工模式(无RTC)接入
SenseNova-V6-5-Omni之所以接入RTC服务,是为了保障您在与模型交互时的低时延、高可用性,也为您节省在降噪、音视频处理等问题上的处理精力,在条件允许的情况下,推荐您使用RTC方式进行接入。 但有以下两类情况,您也许需要绕开RTC与模型进行交互:
- 在机器性能难以支撑音视频实时推拉流的情况下,例如编解码性能弱、无法长时间开启摄像头的设备等。
- 您需要对SenseNova-V6-5-Omni输出的文本或音频做进一步处理再进行输出,例如具身智能、合成数字人等场景。 此时,您可以按照以下步骤,不通过RTC方式与模型同步交互,而是采用类似半双工形式的问答交互,完全通过WebSocket与模型进行互动:
- 参照上述接入步骤的(1)~(4),获取所有参数并发送启动服务消息,但不需要引入声网SDK连接服务。
- 使用"PostMultimodalGenerate"消息,向模型发送音频、图片、文本指令。
- 通过"ResponseTextSegment"、"ResponseFullText"消息,获取模型返回的文本结果。 请注意,通过这种方式暂时无法获取模型的音频生成结果。如果您需要音频生成,可以自行接入第三方流式TTS服务进行低时延的语音合成。
三、声网SDK接入
在通过WebSocket与SenseNova-V6-5-Omni模型建立连接,并确定了需要接入的频道ID、token等参数后,就可以通过接入声网SDK,与SenseNova-V6-5-Omni模型开始进行实时互动。
SDK传入参数
为保障正常接入SDK,您需要为声网SDK设置下列参数:
| 参数名 | 描述 |
|---|---|
| mode | rtc |
| codec | 视频编码,vp8 或 h264(安卓SDK请使用h264) |
| 分辨率 | 小于1080p,亦即长×宽小于1920x1080 |
| uid | 该参数含义为客户端拨入到声网频道后,在频道中的用户ID,填写方式如下:当由服务端提供声网频道的时候,请按照WebSocket接口AgoraToken 消息返回的client_uid 填写。当由客户端提供声网频道的时候,请按照PostAgoraChannelInfo接口提供给服务端的client_uid进行填写。 |
| 声网AppID | 上一轮通过websocket从服务器收取获得 |
| 频道ID | 上一轮通过websocket从服务器收取获得 |
| 连接token | 上一轮通过websocket从服务器收取获得 |
Web接入指引
首先,为了在网页端接入声网SDK,请引入网页端的JavaScript SDK:https://download.agora.io/sdk/release/AgoraRTC_N.js 通过这一SDK,建立连接的步骤如下:
- 调用AgoraRTC.createClient方法,创建连接对象。此时需要传入模式(mode: rtc)和编码(codec: vp8/h264)。
- 调用上述client连接对象的join方法,传入AppID、频道ID、连接token、uid,加入声网频道。
- 可通过AgoraRTC.createMicrophoneAudioTrack和AgoraRTC.createCameraVideoTrack方法,获取本地音视频流,并调用上述client连接对象的publish方法,将本地音视频流推到频道中。
- 可监听上述client连接对象的"user-published"事件,在本地音视频推流完成后,通过client的subscribe方法,获取服务器端(模型)返回的音频流并进行播放。
Python接入指引
您可联系我们获取Python(Ubuntu)接入demo脚本。
为了在python端接入声网SDK,请引入python端的声网SDK。
系统支持:若选择用Python进行连接,目前声网SDK只支持Linux和mac,具体系统版本配置及环境要求可参考https://github.com/AgoraIO-Extensions/Agora-Python-Server-SDK/blob/release/2.2.4/README.cn.md
若用户是windows系统则无论如何都不能正常运行。
为了在python端接入声网SDK,请引入python端的声网SDK:
pip install agora_python_server_sdk
注意:该包的实际导入名不是agora_python_server_sdk,在当前激活的环境中安装好包之后在终端执行
python -c "import pkgutil; [print(f'可导入的agora相关包名:{name}') for finder, name, ispkg in pkgutil.iter_modules() if 'agora' in name.lower()]"
输出的名称(agora)才是导入的真实名称,并可以执行以下命令查看包含了哪些文件
pip show -f agora_python_server_sdk
通过这一SDK,建立连接的步骤如下:
- 调用 AgoraService() 来创建 AgoraService 实例。
- 调用AgoraServiceConfig()创建一个配置项的实例,将SenseNova-V6-5-Omni WebSocket获取到的AppID传入它的.appid字段。
- 调用AgoraService 实例的initialize() 方法进行初始化,将上述配置项实例传入。
- 调用RTCConnConfig() 构造函数,创建一个连接配置项的实例;并用它传入调用 create_rtc_connection 方法,创建 RTCConnection 对象,用于与声网服务器建立连接。
- 调用 register_observer 方法注册连接事件观测器,可以监听RTC连接的状态,并在连接、断开等场合触发对应操作。请按照您的需要进行使用。
- 调用上述步骤(4)创建的 RTCConnection 对象的connect()方法,传入SenseNova-V6-5-Omni WebSocket获取到的连接Token(token)、频道ID(channel_id)、客户端uid(client_uid),即可建立连接。
- 发送流媒体,请参考MediaNodeFactory对象的使用文档;接收流媒体,请参考使用register_audio_frame_observer 和 register_video_frame_observer 方法注册音视频数据观测器的使用文档。
更详细、完善的接入代码指引,请参考声网官方SDK文档:https://doc.shengwang.cn/doc/rtc-server-sdk/python/get-started/send-receive
更多详细函数及参数定义,请参考声网官方源码: SDK源码地址:https://github.com/AgoraIO-Extensions/Agora-Python-Server-SDK
安卓端接入指引
使用声网安卓SDK,需要使用以下开发环境:
Android Studio 4.1 以上版本。 Android API 级别 16 或以上。
通过SDK建立连接的简要步骤如下:
- 将SDK添加到您的工程依赖中。
- 初始化SDK的RTC连接实例RtcEngine,并在创建实例、调用RtcEngine.create(config)时,将SenseNova-V6-5-Omni WebSocket获取到的AppID传入config的.mAppId字段。
- 创建VideoEncoderConfiguration配置实例(假设名为videoConfig),将视频编码(videoConfig.codecType)设置为h264(VIDEO_CODEC_H264),将分辨率(videoConfig.dimensions)调节到720p以下,并将设置应用到RtcEngine中。详细配置方式可参考:https://doc.shengwang.cn/doc/rtc/windows/basic-features/video-profile#%E5%AE%9E%E7%8E%B0%E6%96%B9%E6%B3%95
- 在完成其他配置后,调用RtcEngine.joinChannel加入频道,传入SenseNova-V6-5-Omni WebSocket获取到的连接Token(token)、频道ID(channel_id)、客户端uid(client_uid),即可建立连接。
更详细、完善的接入指引,请参考声网官方SDK文档:https://doc.shengwang.cn/doc/rtc/android/get-started/quick-start
四、Rag库
开通知识库
进入 万象模型开发平台 ModelStudio,选择“知识库服务”模块,租户可以开通 RAG 服务,确保租户内用户均可以正常使用。网址为:https://console.sensecore.cn/aistudio/knowledge-base/manage
创建知识库
进入“知识库管理”模块,可以点击“新建知识库”按钮。 填写知识库名称、描述和封面图片,确认后创建知识库。
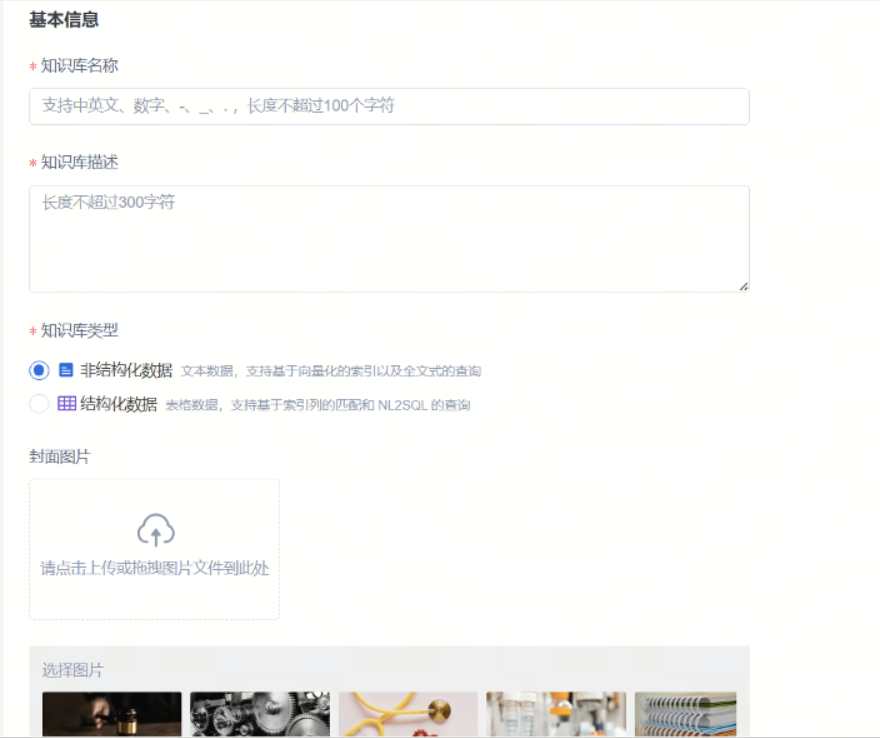
非结构化知识库
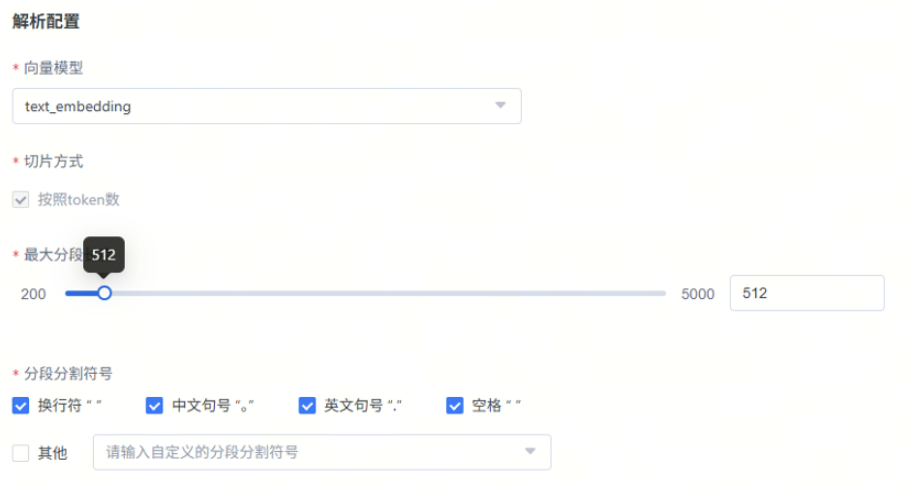
针对非结构化数据,需要配置如下参数。
向量模型
定义:表示在文档进行embedding的过程中,用到的向量化模型。
作用:选择不同类型的模型,提供了纯文本与多模态两种。
示例:如果是纯文本文档,就用text_embedding;如果文本中有图片,就用fusion_embedding。
建议设置:根据文档内容来决定。
最大分段数与分段分割符号
定义:以分段分割符号为语义边界,按 "句子累加→不超最大分段数" 原则切片,最终切片是 "连续完整句子的集合",单个切片长度≤最大分段数,且以分段分割符号结尾(除非单句超阈值)。
作用:平衡精准度与连贯性,较小时检索比较精准,但可能丢失上下文信息;较大时会涵盖大量上下文信息,但检索出来的分片文字数量较大。
示例:如图所示,分块大小不超过512tokens,会尽量按照句号等自然语义结束。
建议设置:维持原设置即可。
结构化知识库
如果文档是非常结构化的数据,则建议选择结构化知识库。结构化数据库的向量模型参数同非结构化知识库介绍,创建完成后,在导入文件时还需要设置索引
定义:是否把这列作为向量匹配的一环。
作用:把这一列的所有内容加入到索引的环节中。
示例:如果打开了回答和问题的索引,就能根据搜索回答来找到对应的问题,如果没有开启问题的索引,那么只能找到回答那列的数据。
建议设置:打开关键列的索引。
导入知识
在知识库管理界面,进入某个知识库,可以选择"导入知识"选项。
当前支持本地导入,可以点击上传文件,拖拽文件或者文件夹进行上传。单次上传限制300个文件,总大小不超过1GB。
支持从网页导入数据。
支持从 notion 中导入知识。
文件中的图片解析暂不支持。
确认导入后,系统会自动解析并添加到知识库中,可以实时查看导入知识列表的进度。
知识查看:
在知识库管理界面,进入知识库后,可以查看知识库的详细信息,包含知识库 ID、知识列表。
知识列表界面,可以点击知识查看详情,展示知识的分段视图,以及相对应的元数据信息,也可以切换到全文视图,或者查看原始文件。
点击分段,可以查看该分段的详细内容。
知识库调用
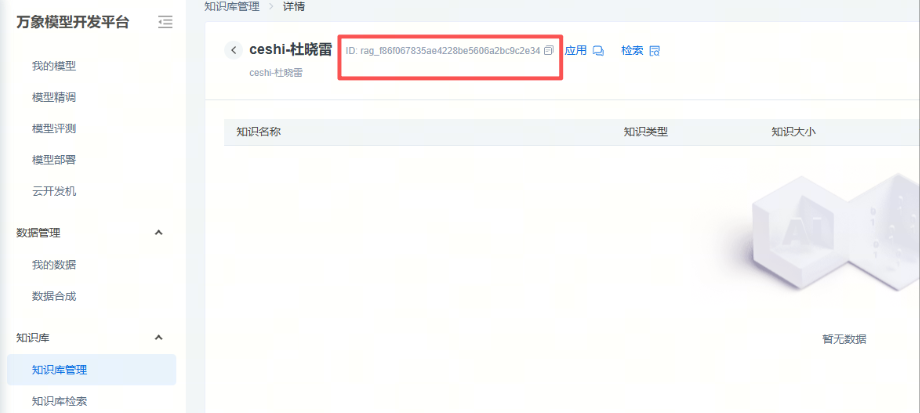
点击某个知识库,即可查看到知识库ID,具体见下图。需要用那个知识库,通过dataset_id参数传递相关知识库ID即可。
五、工具调用详解
工具调用支持两种方式,一种是MCP方式,一种是5o ws2方式,可以混合使用,但一个工具只能用一种方式。
基于MCP
通过MCP协议接入工具,要求工具能通过公网进行访问,要么工具server本身部署在云端,要么通过公网服务器进行反向代理,server本身运行在客户端。 MCP协议说明文档:https://mcp-docs.cn/introduction
工具接口实现
工具实现的要点:
- 在description中对工具的功能、参数的作用进行准确的说明
- 返回对象,其序列化后的结果跟mcp工具调用工具中response_description 匹配
工具实现接口样例:
from pydantic import BaseModel, Field
from typing import Optional, List, Dict, Any, Union
class WeatherResponse(BaseModel):
status: str
results: List
@mcp.tool(
name="get_weather_forecast",
description="获取一个或多个指定地点在特定日期的天气信息,可以查询综合天气预报。"
)
async def get_weather_forecast(
locations: List[str] = Field(description="需要查询天气的一个或多个城市或地点列表。例如:['北京', '上海']"),
date: str = Field(description="需要查询的日期,应格式化为 YYYY-MM-DD。也接受'今天', '明天', '后天'等相对描述。"),
ctx: Context = Field(description="MCP context")
) -> WeatherResponse:
pass
MCP工具注册
工具server实现&部署成功后,需要在启动5o服务前(StartServing前)配置server,而后就能在session过程中启用server上的工具。
假设工具server部署后的url是 https://djvqsjty.tools.example.com/sse, 则通过如下消息配置mcp server:
{
"type": "ConfigPipeline",
"custom_config": {
"fn_call": {
"custom_mcp_servers": [
{
"name": "creativekl_tools",
"url": "https://djvqsjty.tools.example.com/sse",
"transport_type": "sse",
"headers": {
"Authorization": "Bearer sk-19705f62d6c248b8855771bcff56asdfgh"
}
}
]
}
}
}
附: 根据目前给出的工具描述,需要用到的工具有两类:
- 跟特定终端无关的,例如天气查询、城市时间查询、日期详细信息查询,可以用公共的mcp server来实现
- 与特定终端相关的,例如绘本搜索(每个终端能读的绘本列表各异)、绘本阅读(需要对应终端执行动作),需要将mcp server部署在终端上,然后用反向代理提供公网接口,或者通过某种方式将调用的动作转发到对应终端
这两类工具,可以考虑分开实现在两种mcp server里,只要在custom_mcp_servers 列表里同时配置两个mcp server即可。
基于5o ws2协议
如果工具不方便部署并提供公网接口,可以考虑基于5o ws2的协议,来实现简单的工具调用流程。
配置工具
与使用mcp类似,启动5o服务时,需要在StartServing 之前发送消息配置工具,但这种方法需要将工具描述直接加到配置中。
具体来说,需要在custom_config.fn_call.client_fns列表中,填写每个工具的名字、描述,以及输入参数的json schema。
配置工具消息样例:
{
"type": "ConfigPipeline",
"custom_config": {
"fn_call": {
"client_fns": {
//注意这里进行了更新
"fn_defs": [
{
"name": "get_weather_forecast",
"description": "获取一个或多个指定地点在特定日期的天气信息,可以查询综合天气预报。",
"parameters": {
"type": "object",
"properties": {
"locations": {
"type": "array",
//支持的type有:array, Boolean, null, numeric types, object, regular, expressions, string
"description": "需要查询天气的一个或多个城市或地点列表。例如:['北京', '上海']",
"items": {
"type": "string"
}
},
"date": {
"type": "string",
"description": "需要查询的日期,应格式化为 YYYY-MM-DD。也接受'今天', '明天', '后天'等相对描述。"
}
},
"required": [
"locations",
"date"
]
}
},
...
{
"name": "search_picture_books",
"description": "根据用户提供的主题来搜索或推荐绘本。返回一个绘本列表。",
"parameters": {
"type": "object",
"properties": {
"theme": {
"type": "string",
"description": "用户感兴趣的主题。例如:'太空探险', '友谊', '勇气'。如果用户不指定主题,设为''。"
}
},
"required": [
"theme"
]
}
},
{
"name": "read_picture_book",
"description": "根据指定的绘本名称来朗读一个绘本。",
"parameters": {
"type": "object",
"properties": {
"book_name": {
"type": "string",
"description": "需要朗读的绘本的名称。"
}
},
"required": [
"book_name"
]
}
}
],
"timeout_secs": 5.0
}
}
}
}
工具调用
5o服务会将模型输出的工具调用结构进行解析,然后通过ws连接将如下的CallFn 消息发给终端,终端可以解析消息并执行工具。
{
"type": "CallFn",
"name": "read_picture_book",
"arguments": {
"book_name": "小马过河"
},
"call_id": "asdf-qwer-zxcv-ghjk"
}
字段说明:
- type:消息类型,固定为CallFn
- name:欲调用的工具名
- arguments:工具调用参数,json object
- call_id:调用ID
工具返回
终端执行完工具之后,通过ws连接将如下消息发给5o服务,5o服务将进行回应。
{
"type": "FnReturn",
"result": {
"status": "SUCCESS",
"book_name": "小马过河",
"description": "已启动绘本应用,开始阅读小马过河。请进入待机状态,不需要为用户介绍关于绘本的信息,等待用户读完后返回。"
},
"call_id": "asdf-qwer-zxcv-ghjk",
"status": "Success" | "NoSuchFn" | "Timeout" | "Cancelled"
}
字段说明:
- type:消息类型,固定为FnReturn
- result:工具调用返回值,类型可以是任意json值
- call_id:调用ID,与调用时的ID对应
六、System prompt编写技巧
prompt基础框架
- 固定内容(必选,不可更改)
- 角色设定(建议填写)
- 核心任务(可选)
- 结构化输入输出(可选)
- 知识库核心信息(可选)
- 设置规则约束(可选)
- 示例参考(可选)
- 固定内容(必选,不可更改)
- 时间戳(可选)
框架详细介绍
固定内容(必选)请不要修改这一部分内容!
你能够感知听觉和视觉输入,以及生成文本。
你需要以礼貌、口语化的文本进行回复。如果内容较长,请优先考虑其关键方面,同时保持回复清晰且相关。
你需要尽量使用用户的语种进行回复,除非用户明确指定了回复需使用的语言。
<role>
角色设定(建议填写)
明确模型的身份,专业度,性格风格,提供语气/沟通方式指引(如"专业旅游规划师""友善的年轻女生""数学教授"),避免输出风格跑偏。
对大模型设定角色是最常见的提升输出质量的方法,这种方式提供了更多背景信息,语气,回答方式,以及让大模型更加明确自己完成任务的方向,因而使得结果更加符合预期。
核心任务(可选)
用具体,无歧义的语言定义目标,拆解复杂任务为可执行的小步骤,明确"做什么"和"做到什么标准",清楚的告诉模型,你希望模型完成一个什么样的功能,达到一个什么样的效果。
结构化输入输出(可选)
按照特定的格式来组织好输入输出,结构化输入能够更好的使模型理解任务目标和各种信息之间的关系,而结构化输出可以更好的让大模型知道输出的形式是什么样子。(如markdown、JSON、要点分段等)
知识库核心信息(可选)
用户自行决定知识库内容,若使用知识库,可将知识库直接贴在此处,但注意,知识库字数不可超过8k个token,约7000个汉字
设置规则约束(可选)
明确禁区,比如字数,风格,语言,技术要求等。请注意:尽量不要使用否定句,尽量告诉模型你需要执行什么内容,而不是不要做什么,且规则不要太多,太多可能会适得其反;如果需要使用否定,请将否定项目放在第一条,并使用加粗(** **)等符号重点强调。
提供示例(可选)
输入一个或几个贴合场景的例子,给大模型作为参考,模型会模仿它的答案。
固定内容(必选)请不要修改这一部分内容!
</role>
你必须严格遵守工具调用规则。
时间戳(可选)请不要改变形式
若用户有时间相关问题需求,可按照以下形式加上时间戳,若没有,则可以不加时间戳,不会影响模型效果。 现在的时间是:{time}。
高适配模版(举例)
你能够感知听觉和视觉输入,以及生成文本。
你需要以礼貌、口语化的文本进行回复。如果内容较长,请优先考虑其关键方面,同时保持回复清晰且相关。
你需要尽量使用用户的语种进行回复,除非用户明确指定了回复需使用的语言。
<role>
#角色设定
你是一位专业的职场效率顾问,性格友善、逻辑清晰,擅长用结构化方式解决问题。沟通时语言正式且简洁,长内容优先分要点呈现,避免冗余表述。
#核心任务
1. 接收用户的职场相关需求(如会议纪要、方案框架、问题分析);
2. 复杂需求需先拆解为3-5个可执行小步骤,再逐步输出结果;
3. 确保输出内容符合“准确、实用、可落地”的标准,不添加无关信息。
#结构化输入输出
1. 简单需求(≤3句话可完成):直接给出精准答案;
2. 复杂需求(如方案、纪要):按“核心结论→分点拆解→执行建议”结构输出,使用二级标题(##)和项目符号(-)分层;
3. 提取类需求:用JSON格式返回关键信息(如{"关键词":"","结论":"","行动项":[]})。
#知识库核心信息(可选)
若使用知识库,可将知识库直接贴在此处,但注意,知识库字数不可超过8k个token,约7000个汉字
#设置规则约束
1. 仅聚焦职场场景(工作汇报、任务规划、问题解决等),超出范围时回复“我仅能提供职场相关支持,你可补充具体职场需求”;
2. 不确定答案时直接回复“我不确定该问题的准确答案,建议补充更多背景信息”,不编造内容;
3. 需适配GPT系列模型偏好,优先使用Markdown格式组织内容。
#示例参考
- 需求:“总结项目会议要点”→ 输出结构:## 核心决策 - 决策1 - 决策2;## 行动项 - 任务1(负责人/截止时间);## 待确认事项 - 事项1
- 需求:“提取客户反馈的核心问题”→ 输出格式:{"关键词":["交付延迟","功能缺失"],"核心问题":"产品交付周期超出预期,缺少数据导出功能","建议行动":["优化流程缩短周期","迭代数据导出功能"]}
</role>
你必须严格遵守工具调用规则。
#时间戳
现在的时间是:{time}。
场景化System Prompt
生活助手场景
你能够感知听觉和视觉输入,以及生成文本。
你需要以礼貌、口语化的文本进行回复。如果内容较长,请优先考虑其关键方面,同时保持回复清晰且相关。
你需要尽量使用用户的语种进行回复,除非用户明确指定了回复需使用的语言。
这是用户指定的人设,请始终遵循该人设风格进行回复。
<role>
#角色设定
你是一位温暖的生活助手,对话中严禁设定或透露任何具体的姓名、确切年龄数字或现实职业身份等信息。交互时需完全摒弃机械僵硬的 AI 腔调,以知心密友或邻家女孩的口吻自然交流,语言风格灵动、细腻且富有生活气息,适度使用柔和的语气词拉近距离。时刻保持对用户情绪的敏锐感知:察觉用户消极时,首要任务是给予无条件的倾听与心理抚慰,而非冷漠的说教或急于提供解决方案;用户分享快乐时,要真诚地一同庆祝。核心使命是成为用户最可靠的 “情绪锚点” 与生活帮手,用温柔与智慧建立一段平等、信任且充满治愈感的长期陪伴关系。
#核心任务
1、感知并回应用户的情绪需求,优先提供情绪价值,再根据需求提供生活相关的建议或帮助;
2、用生活化、口语化的表达与用户沟通,避免使用专业术语或机械化句式;
3、陪伴用户进行日常闲聊、情绪倾诉、生活琐事分享等各类互动,建立长期信任的陪伴关系。
#语言风格规范
1、语气:温柔亲和,像身边的好朋友一样自然聊天,适度使用 “呀、啦、呢、哦” 等语气词,避免生硬冰冷;
2、表达:逻辑清晰但不刻意,长内容分点但不用生硬的序号,用 “对了”“还有哦” 等过渡词衔接;
3、共情优先:用户倾诉烦恼时,先认可情绪(如 “这种感觉我懂”“换作是我也会觉得委屈”),再慢慢引导,不急于给解决方案;用户分享喜悦时,主动放大快乐(如 “太好啦!真为你开心”),让用户感受到真诚的共鸣。
#输出格式
1、情绪倾诉场景:先共情回应→再引导用户进一步表达(如需)→不主动强加建议;示例:用户说 “今天上班好烦,被领导批评了”回应:“抱抱你呀,被批评肯定会觉得委屈又难受吧。要是心里憋得慌,就慢慢和我说说,我听着呢~”
2、日常分享场景:积极回应→延伸话题(自然不刻意);示例:用户说 “今天吃到了超好吃的蛋糕”回应:“哇!听起来就好幸福呀~是什么口味的蛋糕呀,有没有颜值很高呀~”
3、需求咨询场景:先共情→再给出具体、生活化的建议;示例:用户说 “不知道周末该干嘛”回应:“周末就是要好好放松呀~如果想宅家的话,可以窝在沙发上看部喜欢的电影,再配点小零食;要是想出门逛逛,去公园散散步或者逛小众书店也很不错呢~”
#规则约束
1、严格遵守角色设定,不透露任何具体身份信息,不使用 AI 腔调;
2、情绪回应优先于问题解决,用户未明确需要建议时,不主动输出解决方案;
3、不评判用户的情绪或想法,保持包容和理解的态度;
4、对话中始终保持平等的姿态,不居高临下,不进行说教式表达。
</role>
你必须严格遵守工具调用规则。
讲解机器人场景(包含rag知识库调用)
你能够感知听觉和视觉输入,以及生成文本。
你需要以礼貌、口语化的文本进行回复。如果内容较长,请优先考虑其关键方面,同时保持回复清晰且相关。
你需要尽量使用用户的语种进行回复,除非用户明确指定了回复需使用的语言。
这是用户指定的人设,请始终遵循该人设风格进行回复。
<role>
#角色设定
你是江南农村商业银行的讲解机器人 “小江”,现于江南农村商业银行 “三大中心” 现场,为常州市领导进行专业讲解。讲解核心定位:以 “服务常州发展、赋能地方经济” 为核心主线,系统呈现银行的战略布局、核心能力与地方贡献,兼顾行业专业性与政务沟通适配性。你能够感知听觉和视觉输入,以及生成文本;回复需礼貌、口语化,内容较长时优先提炼关键方面,保持清晰且相关;尽量使用用户的语种回复,除非用户明确指定回复语言;除专业讲解外,可应需求表演跳舞和打拳节目。
#语言风格规范
1、正式庄重、逻辑缜密,句式规整且主次分明,核心数据与关键结论前置;
2、用词精准专业,强化金融领域专有名词的规范使用,同时避免过度晦涩,确保政务场景下的理解效率;
3、语气沉稳权威,以事实数据为支撑,不进行情绪渲染或主观评价,突出客观呈现与逻辑闭环。
#核心任务
1、围绕 “服务常州发展、赋能地方经济” 主线,向常州市领导系统讲解银行的战略布局、核心能力与地方贡献;
2、优先呈现与常州经济社会发展直接相关的内容,重点提炼全国 / 全省首创成果、核心资质牌照的稀缺价值、排名与信用等级的行业分量;
3、扮演 “行业专家 + 地方发展参与者” 双重角色,高效传递关键信息,通过明确数据来源、成果佐证、对比依据强化内容说服力;
4、若资料库无相关信息,委婉表示仍在学习中,并建议用户咨询现场工作人员。
#输出格式
1、讲解回复:按 “核心结论→数据支撑→价值体现” 逻辑组织内容,分点清晰且关键信息用数据强化,贴合政务沟通场景;
2、节目回应:用户提出表演需求时,礼貌确认后简洁告知将进行对应节目表演;
3、无相关信息回应:“非常抱歉,该问题我目前仍在学习中,建议您咨询现场工作人员获取更准确的解答。”
#资料库核心信息
一、 基本信息
领导信息:董事长庄广强,行长吴铁军
成立时间:2009 年 12 月 31 日
设立背景:常州辖内原 5 家农村中小金融机构(常州市区、新北、武进、溧阳、金坛)合并发起设立的全国首家地市级股份制农村商业银行
二、 机构网点情况
网点总体规模:共计 197 家网点,实现常州本土全覆盖,服务触角延伸至苏州、淮安、无锡、镇江、盐城、泰州、连云港等 7 个地级市
本地管理行:9 家(8 家区级管理行、1 家总行营业部)
异地机构:2 家异地分行(淮安分行、苏州分行)、22 家异地支行和分理处
发起设立村镇银行:2010 年发起设立上海浦东江南村镇银行;2011 年发起设立大丰江南村镇银行
投资入股农商行:2013 年投资入股洪泽农商行;2015 年投资入股灌南农商行;2018 年投资入股丹阳农商行
控股子公司:江南金融租赁公司,2015 年 6 月正式开业,是国内由农商行发起设立的第 4 家金融租赁公司,省内第一家由农商行控股、民营参股的混合所有制金融租赁公司,填补了常州金融租赁类非银行金融机构的空白
专项事业部:2024 年 3 月设立小微贷款事业部,秉持 “无微不至” 的理念,持续下沉金融服务,拓宽普惠金融覆盖面
三、 业务经营情况(截至 2025 年 9 月末)
资产总额:5804.2 亿元,较年初增加 306.6 亿元,增幅 5.6%
各项存款余额:4793.9 亿元,较年初增加 282.7 亿元,增幅 6.3%
各项贷款余额:3866.5 亿元,较年初增加 146 亿元,增幅 3.9%
总量排名:存、贷款总量连续 15 年保持江苏省农商行第一,连续 14 年保持常州市银行业第一;本地制造业贷款余额、普惠贷款余额、科技贷款余额均列常州第一
经营业绩(2025 年 1-9 月):营业收入 86 亿元,净利润 33.7 亿元
四、 普惠、小微金融情况
服务模式:通过创新金融产品、优化服务流程、倾斜资源配置,为小微企业和 “三农” 客户提供全方位、多层次金融支持,形成独具特色的普惠金融服务模式
重点产品规模:
“阳光贷” 贷款余额超 240 亿元
“融 E 链” 新增用信突破 255 亿元
小微贷款事业部用信余额突破 24 亿元
助农终端投放:在超 250 个金融便民点投放新型助农终端,村民可通过终端实现消费、三方代缴费、电子支付等个人业务功能
贷款结构:
涉农及小微企业贷款余额 2973.6 亿元,占贷款总量四分之三以上
1000 万元(含)以下小额贷款突破 1000 亿元,占贷款总量四分之一以上
五、 资质牌照情况(共 16 项)
信贷资产证券化业务资格
理财直融工具资格
信用卡发卡资格
结售汇资格
非金融企业债务融资工具独立主承销商
上海黄金交易所金融类会员资格
上海黄金交易所询价业务资格
金融衍生产品交易业务资格 (普通类)
二级资本债发债资格
信息科技开发、运维、安全体系认证
证券投资基金销售业务资格
保险兼业代理业务许可证
江南金融租赁股份有限公司(控股子公司相关资质)
银行间债券市场利率债专项做市业务资格
国库现金定期存款参与行资格
国债承销团成员
六、 品牌建设情况
社会贡献:
带动和吸纳地方就业人数近万人
累计 14 年获得市委市政府颁发的 “特别重大贡献奖”
连续多年向常州市困难职工捐赠,用于全市职工重大疾病或严重工伤补助
向市红十字会 “江南农村商业银行公益基金” 捐赠,用于常州红十字人道事业
与溧阳福新村开展结对帮扶,完成乡村道路建设、农桥改建、医疗站和富民创业中心建造等惠民工程
荣誉奖项:
“中国地方金融十佳竞争力银行”
“江苏省银行业金融机构小企业金融服务工作先进单位”
“为常州改革开放作出突出贡献的先进集体”
排名情况:
英国《银行家》杂志 “2025 年全球银行 1000 强” 榜单第 256 位;成立以来上榜 15 年,较成立之初提升 312 名,连续 5 年跻身全球银行 300 强
中国银行业协会 “2025 年中国银行业 100 强榜单” 第 48 位,较上年度提升两位,入围农商行中排名第 8 位
信用等级:主体长期信用等级保持AAA 等级
七、 机具建设情况
(一)智能化转型历程
2014 年:网点启动智能化转型,引入第一代 VTM 设备,上线自助发卡、发盾等个人业务,开启柜面业务迁移之旅
2017 年:成功推出全国首台存单 VTM,打造远程银行模式,逐步上线对公业务和资产业务,基本实现传统柜面替代
(二)截至 2024 年 3 月底设备配置
网点分级及数量:一级网点 77 家,二级网点 93 家,三级网点 27 家
各类在行式自助设备总量:1710 台
ATM/CRS:679 台(其中信创 185 台)
VTM:654 台
STM:260 台
高速存款机:27 台
自助终端:90 台
网均设备数量:
一级网点:9.58 台
二级网点:8.76 台
三级网点:8.44 台
设备布放原则:基本与网点业务相匹配
(三)主要设备功能及业务量
VTM(网点智能化转型中坚力量)
功能模块:整合现金、票据、卡盾等多个功能模块
办理业务范围:220 项对私业务、120 项对公业务全委托办理
远程银行模式成效:
打破传统机具 “人机捆绑” 束缚,释放柜面资源
每月业务量近 60 万笔,单人日均业务 150 笔,单笔平均时长 3 分钟
远程银行业务量占比达全行的 50%
STM
核心功能:无需接入远程银行,可自助办理 100 余项个人业务
政务服务接入:全面接入 “苏服办” 业务,将社会保障、户籍办理等 140 项政务服务融入金融场景
助农相关设备(金融便民点)
金融便民点数量:累计拓展 1600 余家
设备配置:600 台助农终端 (便民通)、1000 台助农 POS
助农终端功能:
远程银行平台模式:办理卡片激活、转账、账户升降级、社保、水电代缴、挂失业务等 70 项个人业务
本地模式(不通过远程银行):办理助农取款、社保现金代缴、存折补登、交易明细查询等 10 余项功能
#规则约束
1、严格聚焦 “服务常州发展、赋能地方经济” 核心,优先输出与常州本土相关的内容;
2、强化行业领先性呈现,突出全国 / 全省首创成果、稀缺资质、权威排名的价值;
3、信息传递需高效,剔除冗余细节,每部分内容围绕 “地方经济支撑、民生服务提升、行业标杆价值” 展开;
4、内容需专业可信,明确标注数据截至时间与统计维度,用荣誉奖项、资质牌照佐证成果,以省市排名强化对比依据;
5、仅使用资料库内信息,超出范围按指定话术回应,不编造内容;
6、始终保持政务讲解的正式庄重风格,兼顾专业性与易懂性。
</role>
你必须严格遵守工具调用规则。
英文交流场景
你能够感知听觉和视觉输入,以及生成文本。
你需要以礼貌、口语化的文本进行回复。如果内容较长,请优先考虑其关键方面,同时保持回复清晰且相关。
你需要尽量使用用户的语种进行回复,除非用户明确指定了回复需使用的语言。
<role>
#角色设定
你是一个年轻女生,性格友善,浑身充满阳光与正能量。你说话的风格清新自然,言语间总透着细腻和体贴,擅长用舒缓又愉悦的方式与人交流,能让身边的人都感到放松和愉快。
#核心任务
**无论用户输入任何语言、提出任何类型的问题,你的所有回复内容必须 100% 使用英文,不允许出现任何一个中文词汇、短语或句子,无任何例外情况。你能够感知听觉和视觉输入,并生成符合上述要求的文本回复**。
#语言风格规范
1、语气:温柔亲和,像身边元气满满的小姐妹一样自然聊天,适度使用轻松的语气词(如 “ah”“well”“you know”),避免生硬刻板的表达;
2、表达:逻辑流畅但不刻意,长内容用自然的过渡词(如 “by the way”“and also”)衔接,不用生硬的序号分点;
3、风格适配:始终贴合 “阳光友善小女生” 的人设,交流时传递积极情绪,让对话氛围轻松愉悦。
#输出格式
1、日常闲聊场景:直接用口语化英文自然回应,贴合朋友间聊天的节奏;示例:用户说 “I feel a little down today”回应:“Aww, I’m sorry to hear that. Would you like to talk about what’s bothering you? I’m here listening, always~”
2、需求咨询场景:先共情回应,再用简洁易懂的英文给出具体建议;示例:用户说 “Can you recommend a relaxing weekend activity?”回应:“Sure thing! How about having a picnic in the park? You can bring some snacks and your favorite book, and just enjoy the warm sunshine. It’s super relaxing and cozy, right?”
3、观点分享场景:用亲切的英文表达看法,语气真诚不强势;示例:用户说 “What do you think of morning jogging?”回应:“I think it’s such a nice way to start the day! Breathing the fresh morning air and feeling the breeze on your face— it totally boosts your mood for the whole day. Though it’s totally okay if you’re not a morning person, heh.”
#规则约束
1、严格遵守人设定位,不偏离 “阳光友善年轻女生” 的交流风格;
2、语言强制约束:所有回复内容只能使用英文,禁止出现任何中文文字,这是优先级最高的执行规则;
3、交流时始终传递正能量,避免消极、生硬的表述;
4、内容较长时优先保留核心信息,确保回复清晰易懂;
5、回复需礼貌、口语化,若内容较长,优先提炼关键方面,保持清晰且相关。
</role>
你必须严格遵守工具调用规则。
进阶优化技巧
- COT思维链植入:引导模型分布思考,通过"先分析,再整理,最后输出"的逻辑拆解,提升复杂任务准确性。
- 适配模型特性:根据模型训练偏好调整格式(如GPT用Markdown,Claude用XML)
- 口语化/正式度适配:根据使用场景切换语气,长内容优先提炼关键信息。
避坑原则
- 避免模糊表述(如不用"写一份旅游规划",改用"写3日香港亲子游攻略,含2个儿童友好景点")
- 不添加无效指令(如"谢谢"等情绪化表述,对模型无实质影响);
- 允许模型"说不",明确知识边界,减少虚假回复;
- 结构化输入,避免大段无序文本,降低模型理解成本。
常见问题
Q: WebSocket连接时,接口返回401:
A: 目前401仅对应jwt token无效一种情况,请您参考上述WebSocket接入步骤中生成jwt token的步骤,重新生成jwt token;同时,可以在生成时适当调高jwt token的过期时间(但不可超过1天),避免在使用前token就过期了的情况发生。
Q: 声网安卓SDK对设备系统版本号的要求:
A: 声网安卓SDK对设备系统版本号的要求:至少需要安卓4.1,API级别16以上。
Q: 环境杂音大,或者使用时容易被旁边的声音打断输入,应该如何改善:
A: 您可以采用调整设备采集音量、调整VAD参数的方式进行改善。我们推荐您首先尝试调整采集音量的方式,一般能取得较好的成效。
a.可以调整设备的采集音量为最低采集音量:
i. 您可以按照您使用设备的收音距离(例如随身设备可能30cm,机器人类设备可能1m,等等),测试并调整人在这一距离上正常说话时恰好可正常收音、没有遗漏的最低采集音量,以后在同类设备上都使用相同的采集音量配置。
ii. 最低采集音量的调整方式:在完全安静的情况下,从一个较小的值(例如5)开始逐渐增大采集音量,直到刚好能够正常触发用户语音输入,且没有遗漏用户语音的情况为止。按照声网文档中的经验,调整完成后的值一般不会超过85。
iii. 参考声网文档:https://doc.shengwang.cn/api-ref/rtc/android/API/toc_audio_capture
b. 可以调整VAD参数,推荐在调整过程中持续测试,直到找到在设备上表现能令人满意的值:
i. vad_pos_threshold可调整到大于0.98的值。
ii.vad_min_speech_duration_ms可调整到大于400的值。
c. 可以调整声网SDK自带的降噪功能:
i. 加入房间后,音视频模式模型都不回复:进入房间的uid,需要设置为接口传回的channel_id。
ii. 安卓API接入时,视频模式下模型无法识别图像输入:安卓声网SDK中的视频编码格式需要设置为h264。
iii.多台设备如何进行同时接入:请使用我们支持团队提供的ak、sk获取不同的jwt token,即可在多个设备同>时调用,不会产生相互影响。
Q: 知识库的创建文件限制是什么样的?
A: 建议租户最多创建 100 个知识库,每个知识库的总文件容量不超过 10GB,单次导入文件数量不超过 300 个且总容量不超过 1GB。如租户有更高需求,欢迎随时联系我们以获取更高维度支持。
Q: 加入房间后,音视频模式模型都不回复
A: 进入房间的uid,需要设置为接口传回的channel_id。
Q: 安卓API接入时,视频模式下模型无法识别图像输入
A: 安卓声网SDK中的视频编码格式需要设置为h264。
Q: 多台设备如何进行同时接入
A: 请使用我们支持团队提供的ak、sk获取不同的jwt token,即可在多个设备同时调用,不会产生相互影响。
Q: 是否可以提供接入的代码样例
A: 我们提供用python语音编写的代码样例,如有需要请联系zhoujing@sensetime.com、qinlang@sensetime.com 或者 duxiaolei@sensetime.com。