云服务器 ECS
产品动态
| 版本号 | 更新内容 | 更新时间 |
|---|---|---|
| 云服务器 v0.30.0 | 支持导入自定义镜像和基于实例创建自定义镜像;带外相关异常事件接入事件中心;新增VNC IAM权限点,支持VNC登录独立鉴权 | 2026-03-30 |
| 云服务器 v0.24.0 | 支持创建经典裸金属,并管理实例生命周期;支持跨Region挂载文件存储AFS | 2025-11-30 |
| 云服务器 v0.22.0 | 创建实例时支持自定义hostname及同步创建DNAT进行公网访问;并支持针对已有实例修改hostname | 2025-10-30 |
| 云服务器 v0.20.0 | 支持重装操作系统 | 2025-09-30 |
| 云服务器 v0.18.0 | 支持通过控制台购买CPU及异构类型ECS实例,并管理实例生命周期,支持查看监控等 | 2025-08-30 |
产品概述
云服务器(ECS)是一种稳定可靠、性能卓越、弹性扩展的云计算服务,同时支持虚拟云主机和经典裸金属,包含vCPU、内存、操作系统、网络和磁盘等基本组件;助力用户实时启停和增减计算资源,提升运维效率,支撑业务快速增长。
产品优势
种类丰富
基于不同场景的需求,提供各种类型的实例规格,包含CPU及异构资源;同时支持虚拟云主机和经典裸金属等资源类型
弹性易用
支持自由变更配置,包括实例的计算资源的升降配,存储资源的扩容,计费模式的调整等
性能卓越
高性能CPU和GPU算力,搭配高性能 SSD存储和文件存储AFS,并且提供超高的网络收发包性能;经典裸金属具备物理服务器特征的同时,无虚拟化开销和性能损失,100%释放算力资源。
稳定可靠
单实例可用性达99.975%,云盘可靠性达99.9999999%。实例可实现宕机自动迁移。
产品功能
一站式生命周期管理
支持实例的创建、修改、查询和释放等操作
可挂载多块高性能SSD云盘
支持在线挂载多块性能卓越的SSD云盘
提供多种监控数据
支持对实例的多种指标进行监控,包括CPU、GPU、内存、网络、磁盘等
应用场景
开发及训推
丰富的计算资源,并可以随时升级实例的配置,或者增加实例数量
提供异构、通用型、计算型、内存型等多种实例类型
中间件部署
具备高性能网络和存储等硬件加速能力,按需、弹性使用网络和存储资源
提供可在线扩容或新购挂载的块存储云盘
提供私有网络构建安全隔离的虚拟网络环境
快速入门

1.通过订单购买的方式创建云服务器实例;
2.查看创建后的实例列表及详情信息,并对实例进行管理,例如对运行中的实例进行关机或重启、在详情页对实例重置密码等操作;
3.登录到云服务器实例进行使用,例如部署推理业务等。
用户指南
创建实例
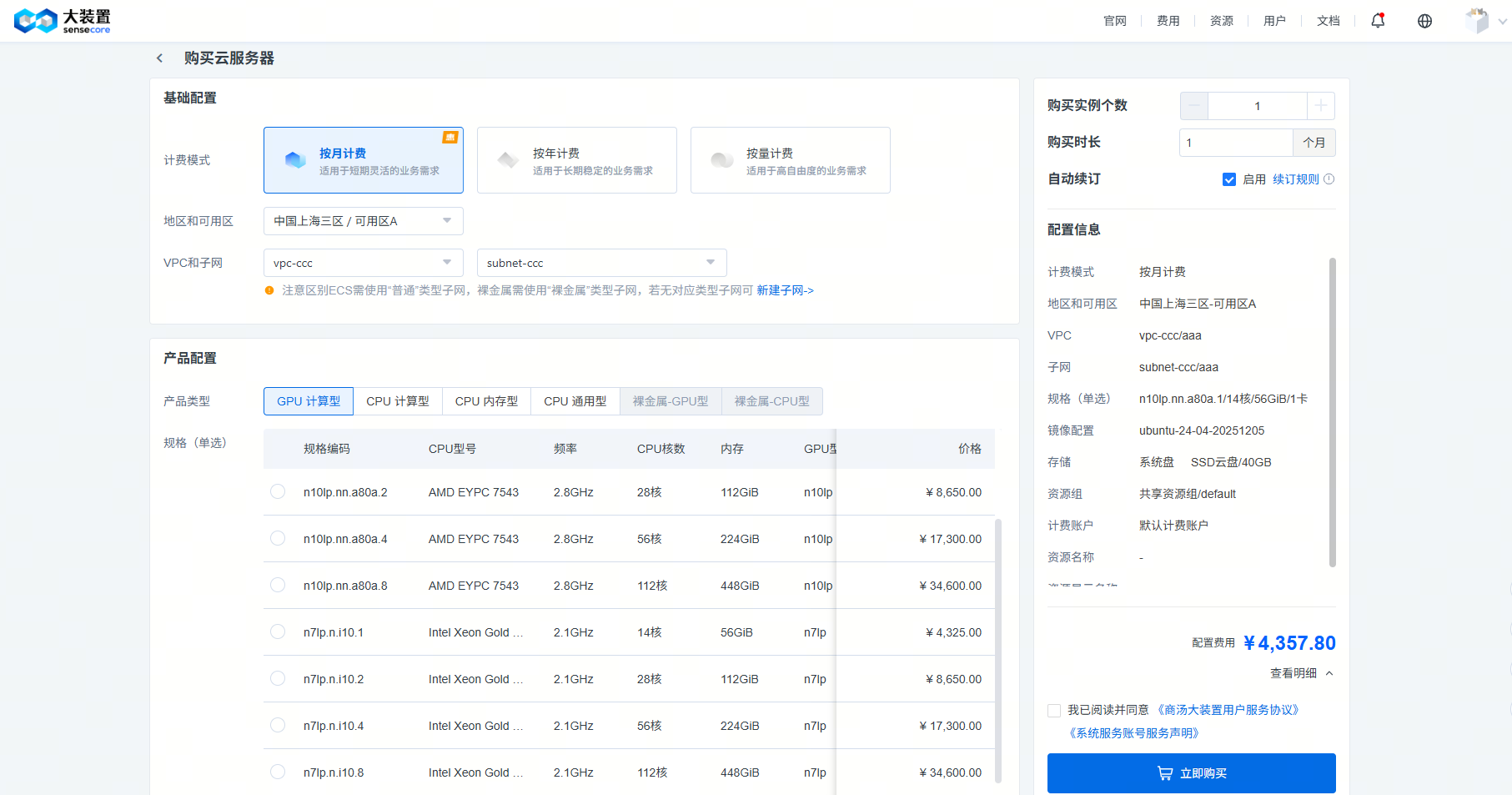
基础配置模块包括计费模式、区域和可用区、VPC和子网等信息:
【计费模式】支持按月计费和按年计费,以及按量计费
【地区和可用区】实例所在地区和可用区,实例创建后不可变更该信息
【VPC和子网】VPC作为一种网络资源起到隔离作用,不同VPC之间的资源默认内网不互通;子网可在VPC内更好细分网段,方便管理及使用;注意区别云主机需使用“普通”类型子网,裸金属需使用“裸金属”类型子网,若无对应类型子网可至VPC页面新建子网产品配置模块包括产品类型及规格、镜像配置、存储、AFS身份识别配置、WEBIDE、公网访问等信息: 【产品类型】提供多种异构及CPU规格,可按需选择;提供虚拟云主机及经典裸金属资源类型 【规格】不同的资源规格选择将对应不同的计费价格
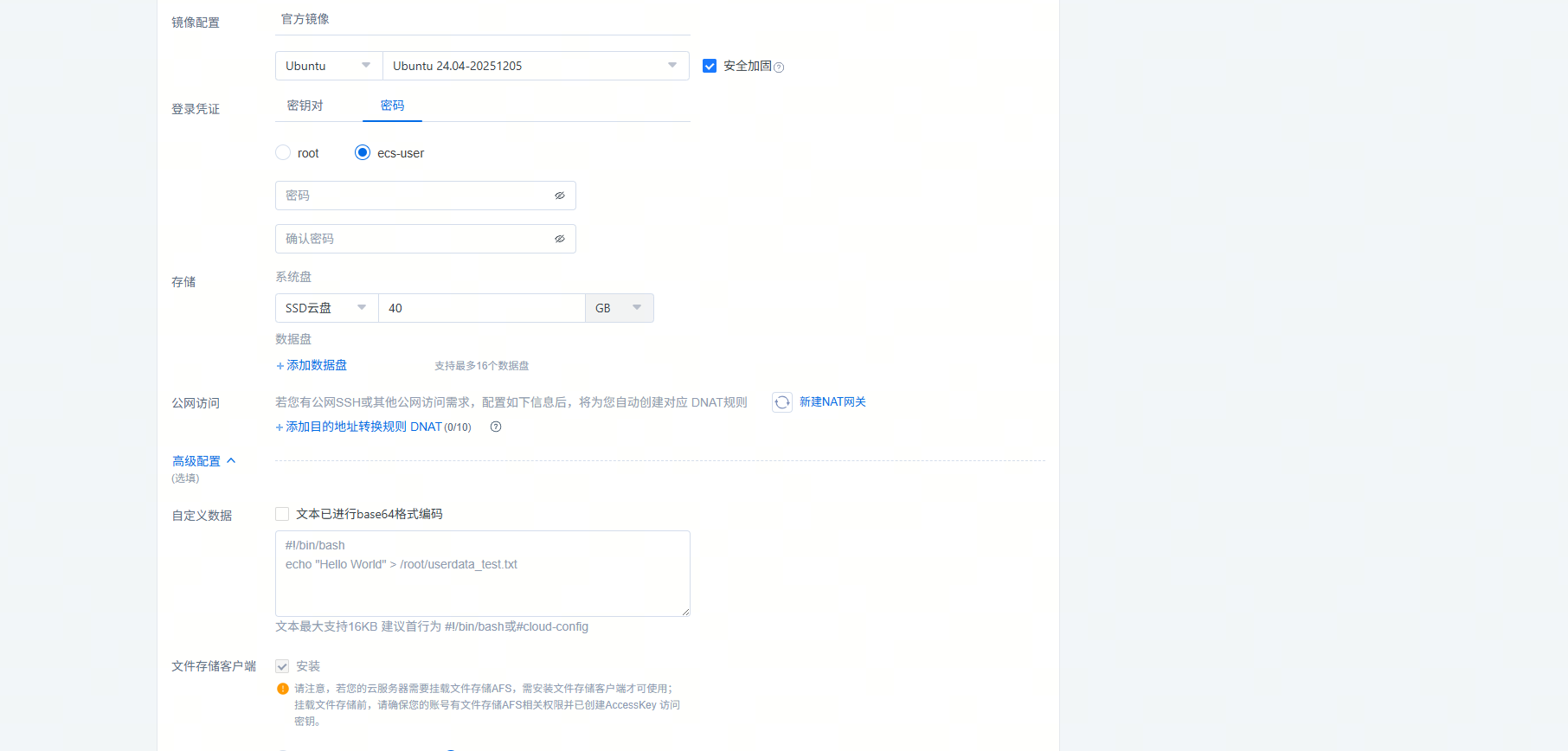
【镜像配置】当前支持官方镜像和GPU镜像(预装GPU驱动和CUDA) 【登录凭证】支持密钥和密码;密码的字符限制为:8~30 个字符,必须同时包含三项(大写字母、小写字母、数字、()`!@#$%^&*_-+=|{}[]:;'<>,.?/中的特殊符号
【存储】云主机默认只有1块云盘系统盘,另外,用户可以添加最多16块云盘数据盘;经典裸金属均仅提供本地系统盘及数据盘。同时支持挂载文件存储AFS,最多可以挂载10个AFS。 【公网访问】若您有公网SSH或其他公网访问需求,配置相关信息后,将为您自动创建对应 DNAT规则并关联至实例
【高级配置】支持配置自定义数据及主机名等信息- 自定义数据:传入用户user-data;支持如下两种格式(详情可参考User-data formats):
- #!/bin/bash:once per instance,仅在主机创建时执行一次
- #cloud-config(仅主机支持该格式,裸金属不支持):always / once per instance,可自定义执行频率,前者always为每次启动时执行,后者once为仅在主机创建时执行一次
- 主机名:默认同实例名称保持一致,同时支持自定义主机名(hostname),主机名的字符限制为:由小写字母、数字、点(.)和连字符(-)组成1-63个字符,以小写字母、数字开头和结尾,不能连续使用点(.)
- 自定义数据:传入用户user-data;支持如下两种格式(详情可参考User-data formats):
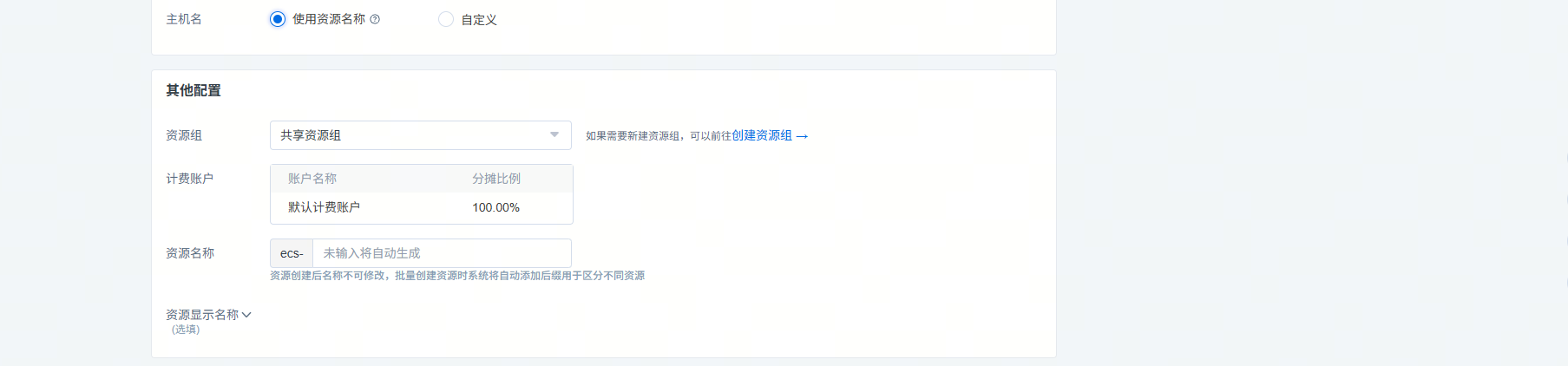
其他配置模块主要包含所属资源组、计费账户、资源名称及显示名称:
【资源名称】字符限制为:由小写字母、数字和连字符(-)组成,1-63个字符,字母或数字结尾
【显示名称】字符限制为:由中文字符、英文字母、数字、下划线“_"和连字符"-"组成,中文字符、英文字母或数字开头,1-256个字符
查看实例列表
用户在控制台面板可以查看创建的实例列表信息,并能对实例进行检索查找目标实例。采用列表的形式展示出用户创建的实例,展示信息包括实例名称/资源唯一标识、状态、规格、镜像、IP地址(包括内网IP和外网IP)、并附有“操作”列,支持开关机(按量计费支持节省停机,即关机不计费)、重启、释放等操作。
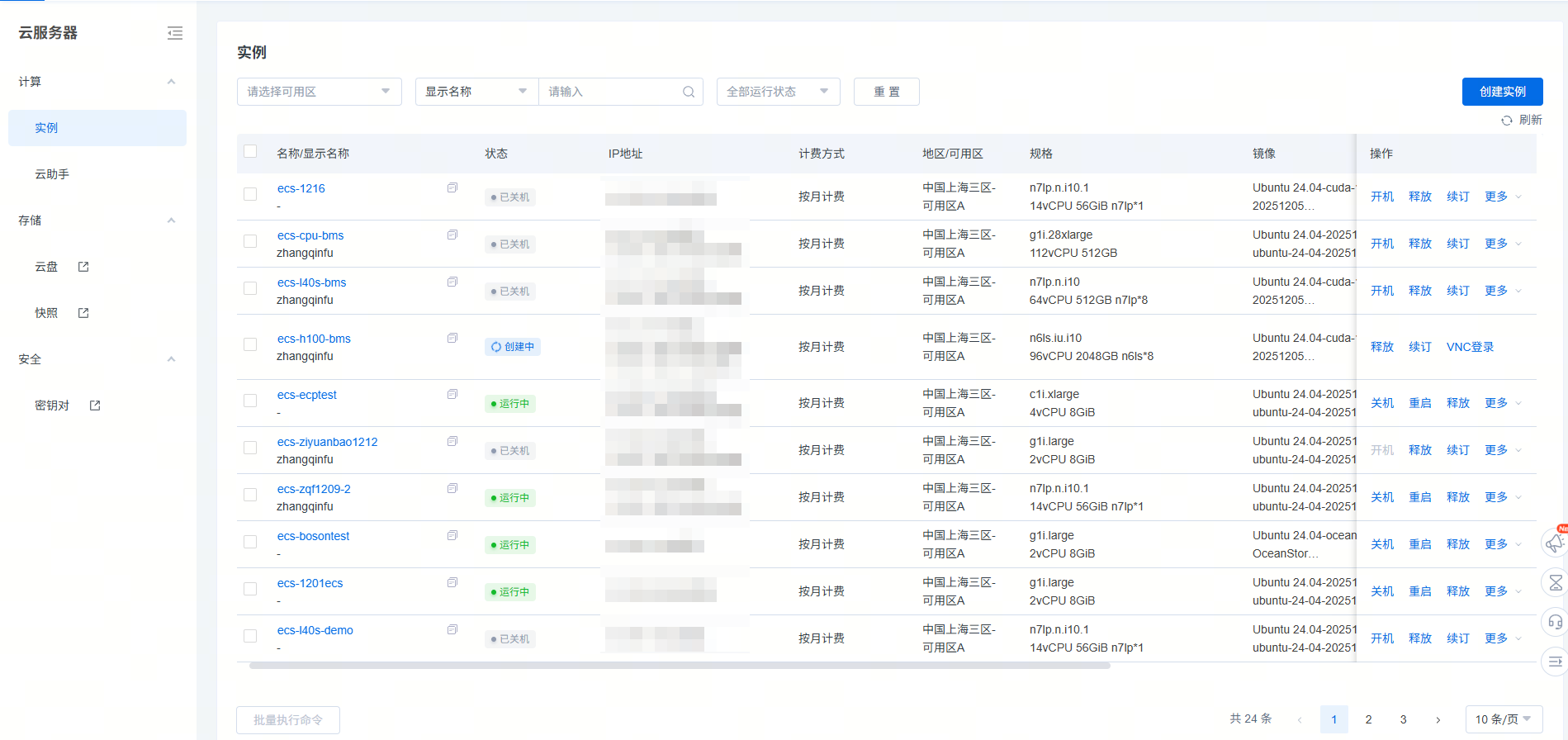
查看实例详情
用户可以通过实例列表页面的某个实例名称跳转到这个实例对应的详情页面,获取关于实例的详细信息。
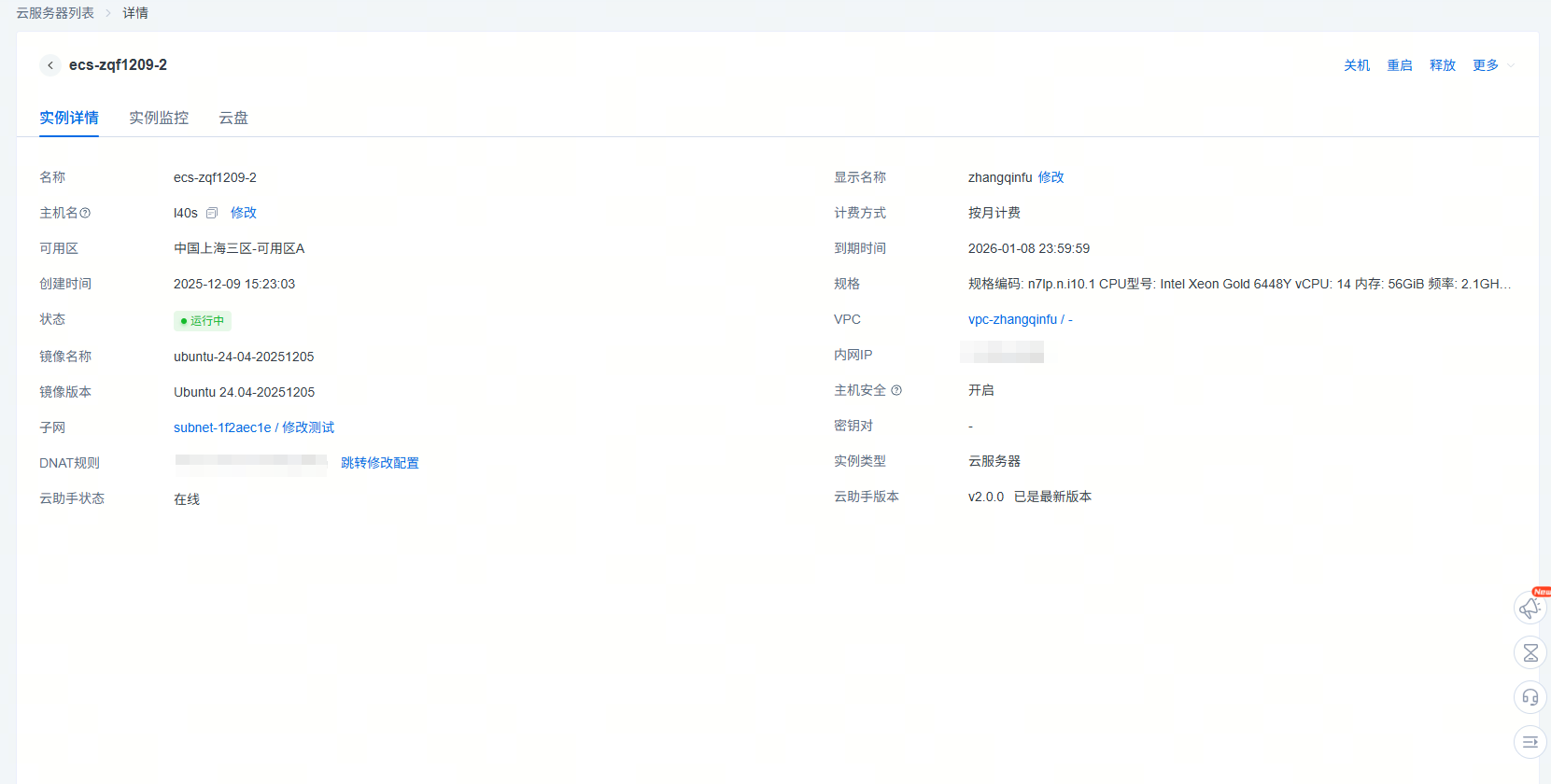 最上方显示该实例名称,实例详情的具体信息包括:实例名称、资源唯一标识、实例状态、地域/可用区、实例规格、镜像、系统盘、数据盘、VPC、创建时间、到期时间、DNAT规则、密码管理,其中实例名称支持修改、密码支持重置、DNAT规则支持配置(跳转到EIP控制台,进行EIP创建和目的地址转换规则配置)。在重置密码之前实例需要处于稳定状态,如运行中状态或已停止,输入新密码并二次确认,重置密码需要重启实例才会生效。
最上方显示该实例名称,实例详情的具体信息包括:实例名称、资源唯一标识、实例状态、地域/可用区、实例规格、镜像、系统盘、数据盘、VPC、创建时间、到期时间、DNAT规则、密码管理,其中实例名称支持修改、密码支持重置、DNAT规则支持配置(跳转到EIP控制台,进行EIP创建和目的地址转换规则配置)。在重置密码之前实例需要处于稳定状态,如运行中状态或已停止,输入新密码并二次确认,重置密码需要重启实例才会生效。
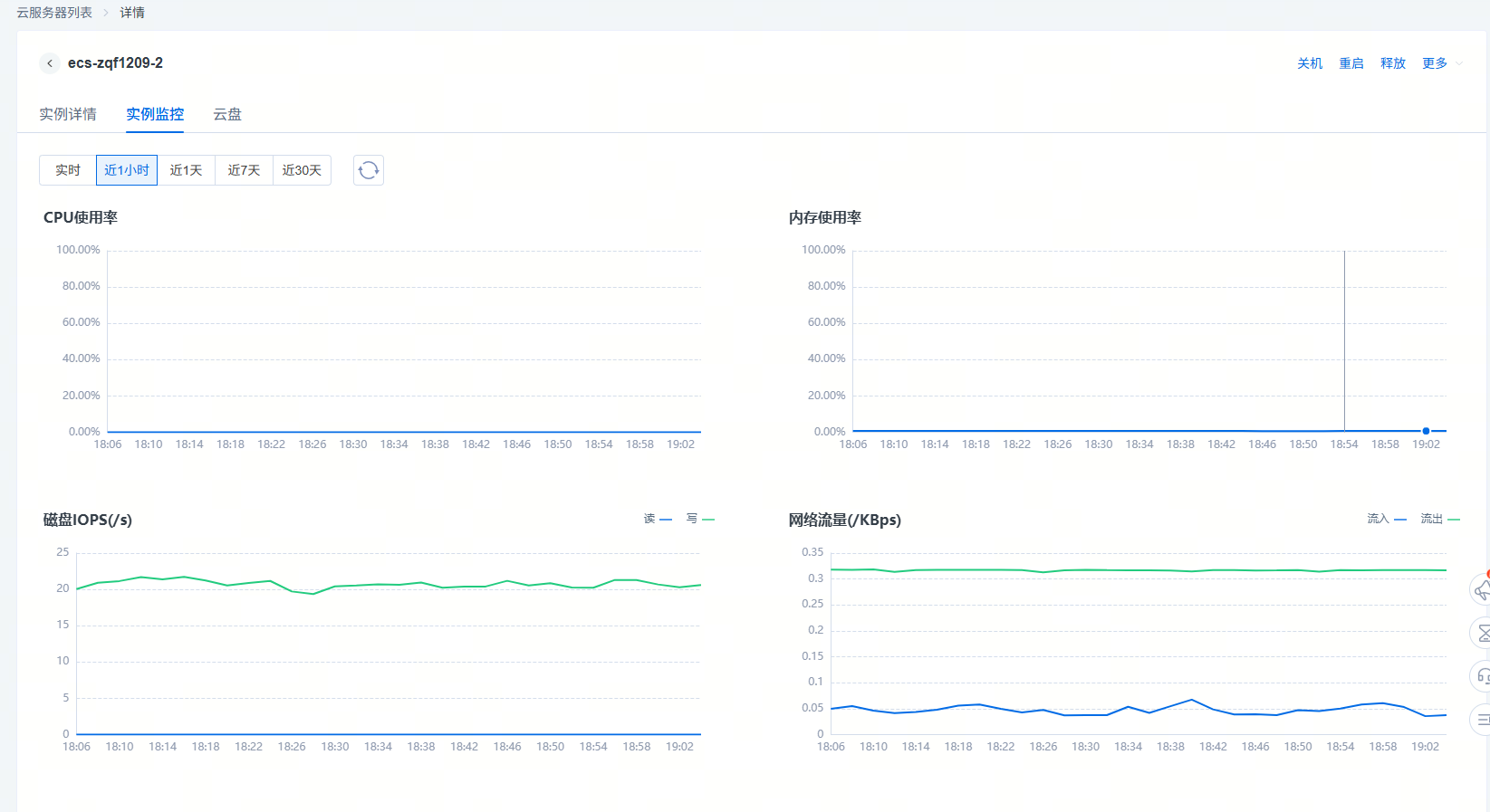
查看实例监控
用户对实例列表中的某个实例点击“监控”,会下沉到【实例监控】页面,通过选择监控时间范围则可以展示出对应的指标情况,时间粒度分为近1小时、近1天、近7天、近30天
VNC登录
VNC登录为用户提供一种通过Web浏览器远程连接到云服务器的方式,在利用其它方式无法登录到实例或者实例处于运行中但操作系统尚未运行起来的情况下,用户可以通过VNC登录连接到实例查看实例操作系统的运行状态或问题。
在实例列表--操作列,【更多】增加【VNC登录】入口,点击后进入VNC登录界面,输入实例的用户名和密码登录到实例操作系统。
更改实例规格
创建实例后,如果当前实例配置无法满足您的业务需求,您可以修改实例规格。
在实例列表--操作列,【更多】增加【更改实例规格】按钮,点击后可以按需进行规格变更,重启实例后新规格生效。
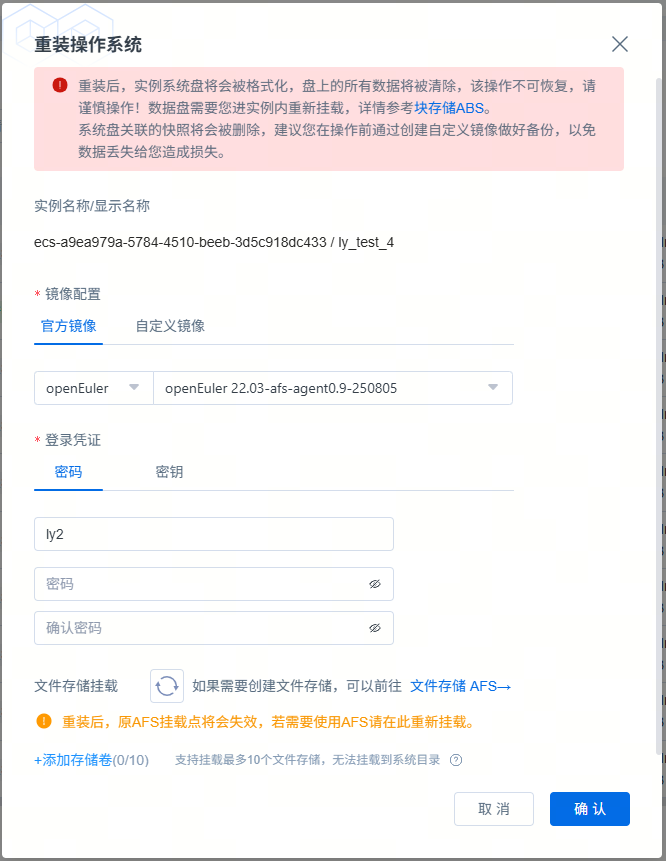
重装系统
创建实例后,如果实例当前的操作系统不满足使用需求时,您可以通过该操作将实例更换为所需操作系统;如果实例遭遇系统故障,您也可以通过该操作将实例恢复到初始状态或恢复到备份的某个自定义镜像的系统状态。
请注意,重装系统是高风险操作,请您关注如下事项,谨慎操作:
- 为避免正在写入的数据丢失等问题,重装系统要求您的ECS实例处理已停止状态。
- 重装后,实例系统盘将会被格式化,盘上的所有数据将被清除,该操作不可恢复,请谨慎操作!数据盘需要您进实例内重新挂载,详情参考块存储ABS。
- 系统盘关联的快照将会被删除,建议您在操作前通过创建自定义镜像做好备份,以免数据丢失给您造成损失。
- 重装后,原AFS挂载点将会失效,若需使用AFS请在重装系统页面重新挂载;挂载文件存储前,请确保您的账号有文件存储AFS相关权限并已创建AccessKey访问密钥,否则将会因无权限导致挂载失败。
- 若您使用自定义镜像重装,非官方镜像相关的OS版本可能挂载失败;目前官方镜像包含常见的Ubuntu24.04、Ubuntu22.04、Rocky9.2、OpenEuler 22.03 SP4等OS。
- 若您使用自定义镜像重装,请确认按照下述 创建自定义镜像 描述,制作镜像前清除Cloud-Init及AFS相关配置,否则将会出现无法注入主机名、密码和挂载AFS行为不可控等问题。
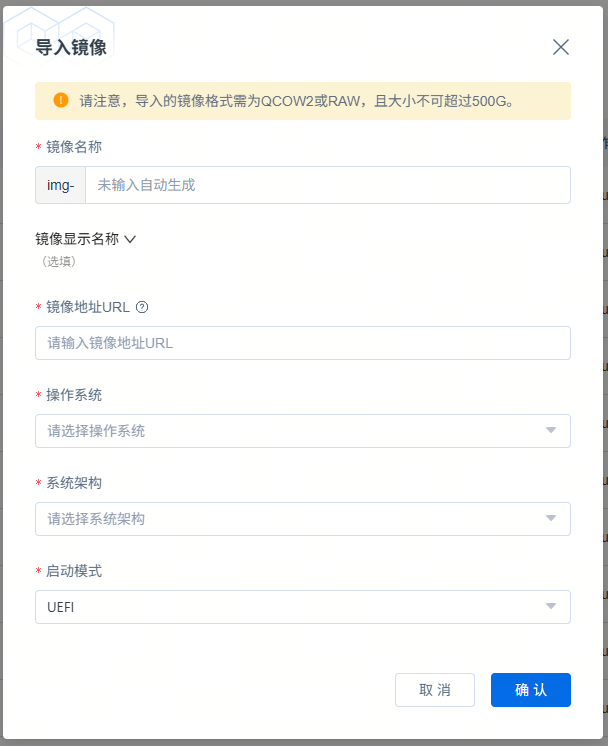
导入自定义镜像
用户可以通过外部文件方式导入自定义镜像。
在镜像列表右上角,点击“导入镜像”,选择可用区,输入镜像名称和镜像地址(对象存储文件URL),选择操作系统和架构,即可导入自定义镜像。
请注意,导入的镜像格式需为QCOW2或RAW,且大小不可超过500G。
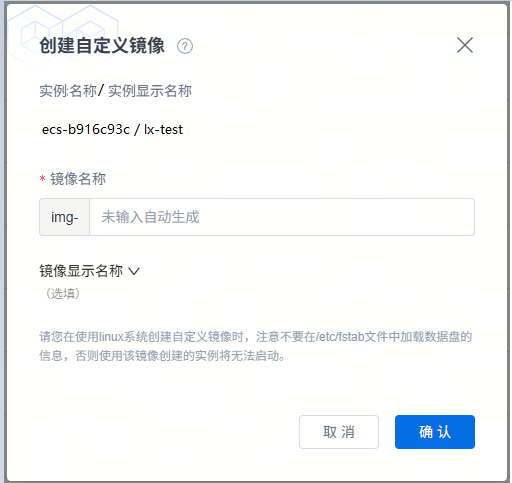
创建自定义镜像
用户可以对ECS实例打镜像,目前仅支持打包含系统盘数据的自定义镜像,打镜像时需关注如下内容:
- ECS实例需为已关机状态;
- 系统盘大小不可超过500G;
- 不要在/etc/fstab文件中加载数据盘的信息,否则使用该镜像创建的实例将无法启动;
- 打镜像前需清除AFS相关配置,否则打出来的镜像创建实例时将导致AFS挂载行为不可控;执行以下命令,删除AFS挂载脚本和systemd AFS服务脚本:
sudo rm -rf /usr/bin/afs_client_mount_*
sudo rm -rf /etc/systemd/system/multi-user.target.wants/quarkfs*
sudo rm -rf /etc/systemd/system/quarkfs*
- 清除Cloud-Init配置:执行以下命令,删除/var/lib/cloud文件。若不删除,使用自定义镜像创建或重装云服务器实例时,将无法注入主机名、密码等信息。
sudo rm -rf /var/lib/cloud
最佳实践
构建开发环境
创建ECS
按照控制台导引创建ECS配置DNAT规则
创建NAT和EIP,添加目的地址转化规则,目的端口指定22(ssh访问端口)挂载文件存储AFS
通过接口方式挂载文件存储AFS,具体操作可咨询产品经理。配置docker,启动docker容器,配置开发环境
以rocky系统为例,配置docker环境:
$ sudo yum install -y yum-utils device-mapper-persistent-data lvm2
$ sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
$ sudo yum list docker-ce --showduplicates | sort -r
$ sudo yum -y install docker-ce docker-ce-cli containerd.io
$ docker -v
$ sudo systemctl restart docker
使用一个预装了AI开发软件包的docker镜像启动docker容器:
$ sudo docker run -it --network host -p 8080:8080 -p 8888:8888 -p 6006:6006 -p 2222:22 registry.cn-sh-01.sensecore.cn/lepton-cci/ubuntu20.04-cuda12.6.1-cudnn-devel:v1.0.0-20240830 /bin/bash
进入容器开启SSH/Jupyter Lab/Tensorboard/Web VSCode 等服务,命令如下:
service ssh start && \
nohup code-server --bind-addr 0.0.0.0:8080 > /dev/null 2>&1 & \
nohup jupyter-lab --ip=0.0.0.0 --port=8888 --allow-root --NotebookApp.token='' > /dev/null 2>&1 & \
nohup tensorboard --logdir=/logs --host 0.0.0.0 --port=6006 > /dev/null 2>&1 &
给上述端口配置EIP和DNAT规则:jupyterlab/8888、tensorboard/6006、vscode/8080,可参考下图:
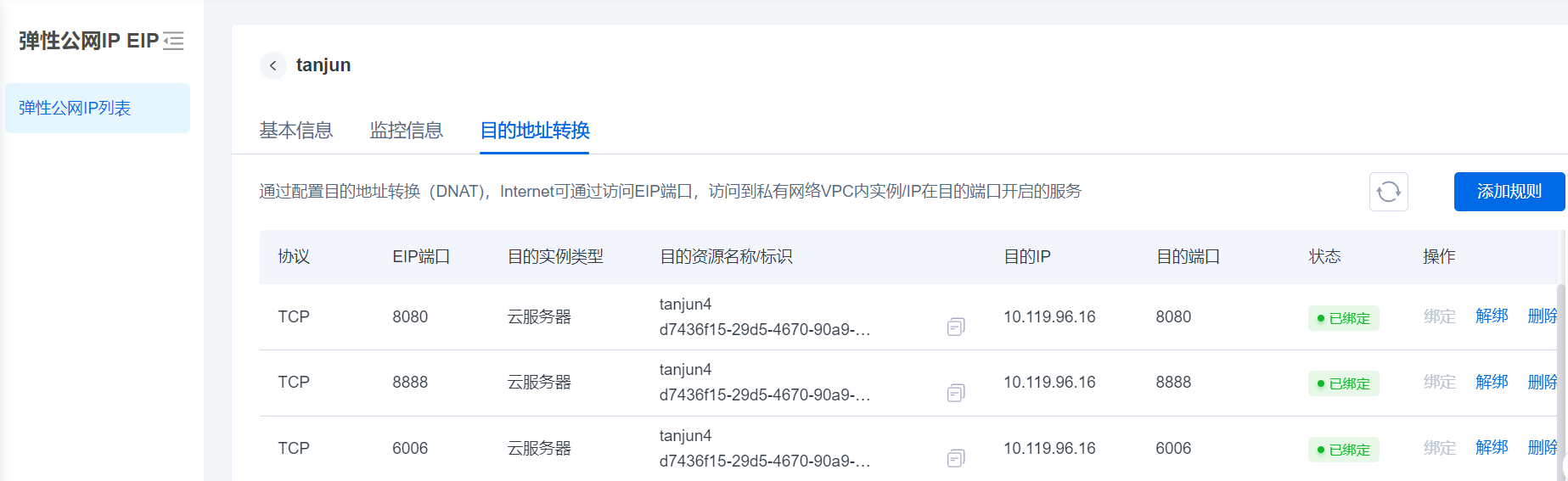
- 在浏览器输入EIP:8888可打开JupyterLab服务
- 在浏览器输入EIP:6006可打开Tensorboard服务
- 在浏览器输入EIP:8080可打开Web VSCode服务
示意图如下:
经典裸金属MIG虚拟化
前提条件
- 所用环境为BMS子产品提供的A100 BM实例
- GPU驱动未被卸载且运行正常
入门使用方法
开启MIG模式
nvidia-smi查看MIG使能情况,Disabled表示未开启
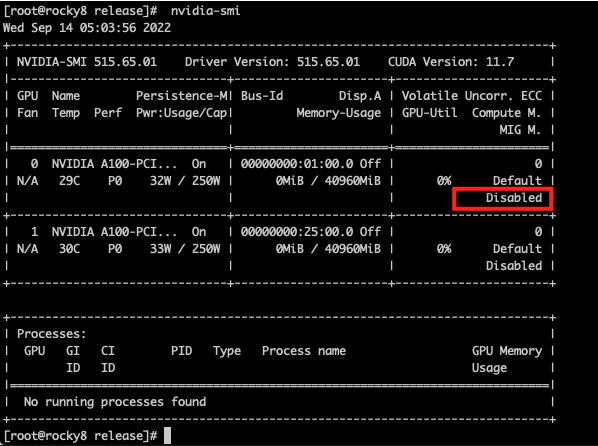
开启和关闭MIG
nvidia-smi -mig 1 # 关闭使用0
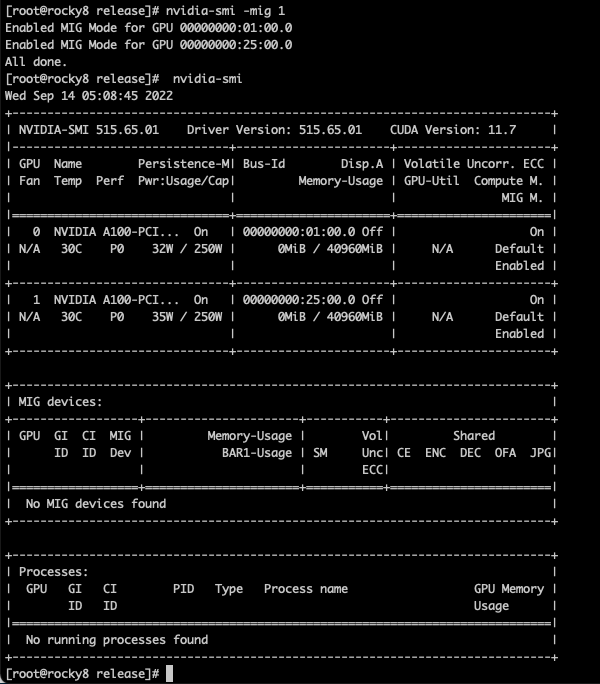
查看MIG实例
查看可用的子GPU类型
[root@rocky8 ~]# nvidia-smi mig -lgip -i 0
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=============================================================================|
| 0 MIG 1g.5gb 19 7/7 4.75 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.5gb+me 20 1/1 4.75 No 14 1 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 3/3 9.62 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 2/2 19.50 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 1/1 19.50 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 1/1 39.25 No 98 5 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+
-lgip参数说明: Lists GPU instance profiles, their availability and IDs. Profiles describe the supported types of GPU instances, including all of the GPU resources they exclusively control.
创造一个profile ID为9的实例
- 也就是MIG 3g.20gb的计算实例
nvidia-smi mig -i 0 -cgi 9 -C
[root@rocky8 ~]# nvidia-smi mig -i 0 -cgi 9 -C
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 1 using profile MIG 3g.20gb (ID 2)
[root@rocky8 ~]# nvidia-smi
Wed Sep 14 16:31:49 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... On | 00000000:01:00.0 Off | On |
| N/A 30C P0 32W / 250W | 19MiB / 40960MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCI... On | 00000000:25:00.0 Off | On |
| N/A 30C P0 33W / 250W | 0MiB / 40960MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 19MiB / 19968MiB | 42 0 | 3 0 2 0 0 |
| | 0MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
运行cuda sample查看实例情况
- cuda sample的下载和编译参考cuda及gpu驱动手动安装 / "Cuda samples验证"
# devicequery可以看到只有一个实例
[root@rocky8 release]# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA A100-PCIE-40GB MIG 3g.20gb"
CUDA Driver Version / Runtime Version 11.7 / 11.7
CUDA Capability Major/Minor version number: 8.0
Total amount of global memory: 19968 MBytes (20937965568 bytes)
(042) Multiprocessors, (064) CUDA Cores/MP: 2688 CUDA Cores
GPU Max Clock rate: 1410 MHz (1.41 GHz)
Memory Clock rate: 1215 Mhz
Memory Bus Width: 2560-bit
L2 Cache Size: 20971520 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 167936 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.7, CUDA Runtime Version = 11.7, NumDevs = 1
Result = PASS
销毁实例
[root@rocky8 ~]# nvidia-smi mig -dgi -gi 1 -i 0
Unable to destroy GPU instance ID 1 from GPU 0: In use by another client
Failed to destroy GPU instances: In use by another client
销毁实例重置
[root@rocky8 ~]# nvidia-smi --gpu-reset
Error encountered during reset of GPU 00000000:01:00.0: Unknown Error
GPU 00000000:25:00.0 was successfully reset.
1 device did not complete reset successfully, and may be in an unstable state. Please reboot your system.
Warning: persistence mode is disabled on device 00000000:25:00.0. See the Known Issues section of the nvidia-smi(1) man page for more information. Run with [--help | -h] switch to get more information on how to enable persistence mode.
[root@rocky8 ~]# nvidia-smi
Wed Sep 14 16:36:26 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... Off | 00000000:01:00.0 Off | On |
| N/A 31C P0 34W / 250W | 0MiB / 40960MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCI... Off | 00000000:25:00.0 Off | On |
| N/A 32C P0 36W / 250W | 0MiB / 40960MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| No MIG devices found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
[root@rocky8 ~]# nvidia-smi mig -dgi -gi 1 -i 0
No GPU instances found: Not Found
关闭MIG模式
nvidia-smi -mig 0
常见问题
云主机
1.我用root创建ecs,为什么创建完成并且绑定了eip/dnat后无法ssh登录?
因为考虑到安全原因,默认禁止root用户登录。如果想用root登录,需要先vnc登录,修改/etc/ssh/sshd_config的參數PermitRootLogin为'yes',然后重启sshd服务。
2.为什么Ubuntu系统的ECS没办法访问CCI应用的内网域名?
CCI应用的内网域名后缀是.local;而Ubuntu系统的本地dns代理中,*.local被认为是本地域名,不会走下一跳的nameserver;故访问不通(rocky操作系统无此问题)。解决办法为:在Ubuntu操作系统的ECS内配置软链接,配置命令为:sudo ln -sf /run/systemd/resolve/resolv.conf /etc/resolv.conf
另外,出于安全考虑,CCI应用的内网域名是禁ping的,请使用telnet或curl命令验证网络连通性。
经典裸金属
- 为什么SSH登录实例一段时间不操作后会自动断开?该怎么解决?
原因分析:根据社区反馈,ssh对应的tcp连接一定时间未活动后,会自动断开。
建议做法:系统默认不对BM实例中的sshd行为做定制调整,当前用户可以按需自行调整相关参数以保持空闲ssh连接。
调整方法:
修改文件:/etc/ssh/sshd_config
在其中添加一行内容,意思是向客户端每60秒发一次保持连接的信号,间隔时间可按需调整
详见 ssh manual (man sshd_config)
ClientAliveInterval 60
如果超过3次未收到客户端反馈才断开连接,可另行调整,0表示不做次数限制
详见 ssh manual (man sshd_config)
ClientAliveCountMax 3
重启sshd服务
sudo systemctl restart sshd
重新ssh登录
补充说明:
服务器端的链接保活方案不一定适用于所有场景,而且ssh连接的断开另外受其他因素影响,如
- 其他因素导致客户端或者服务端主动断开连接
- 客观原因如断网导致连接断开
- 网络流量过高导致连续多次超时或者失败
- 什么是云助手?如何安装云助手客户端?
云助手作为一种自动化工具,可管理软件生命周期、批量管理实例、辅助自动化运维等;
安装步骤:
# 根据实例的所在区域、os类型,选择相应的下载包
ASSIST_PKG=""
# 云助手安装包下载
wget ${ASSIST_PKG} -O /tmp/assist_pkg
# 卸载并安装服务
systemctl is-active lepton-baremetal-assist-client && systemctl stop lepton-baremetal-assist-client
if which rpm >/dev/null 2>&1
then
rpm -qa |grep -q lepton-baremetal-assist-client && rpm -e lepton-baremetal-assist-client
rpm -ivh /tmp/assist_pkg
else
dpkg -l |grep -q lepton-baremetal-assist-client && dpkg -r lepton-baremetal-assist-client
dpkg -i /tmp/assist_pkg
fi
rm -rf /tmp/assist_pkg
# 检查服务是否启动
systemctl is-active lepton-baremetal-assist-client
# 如果是active,说明服务已启动
- 云助手离线该怎么做?
# 检查云助手服务是否存活
systemctl is-active lepton-baremetal-assist-client
# 如果是active,说明服务已启动
# 检查日志是否有异常
tail /var/log/lepton-baremetal-assist-client/lepton-baremetal-assist-client.log
- 常见错误:
| 错误 | 含义 | 补充 |
|---|---|---|
| 与服务网络不通 | 检查配置文件(/etc/lepton-baremetal-assist-client/config.yaml),ASSIST_CLIENT_SERVER_ADDRESS值是否正确 | 云助手服务端地址 上海:https://10.118.0.154:51808 广州:https://10.115.0.154:51808 |
| 安全校验失败 | 检查配置文件(/etc/lepton-baremetal-assist-client/config.yaml),ASSIST_CLIENT_ACCESSKEY、ASSIST_CLIENT_SECRETKEY、ASSIST_CLIENT_UUID是否正确 | ASSIST_CLIENT_ACCESSKEY、ASSIST_CLIENT_SECRETKEY是租户的ak、sk ASSIST_CLIENT_UUID可以在sensecore控制台找到:“资源”->“资源管理”->(具体某个实例)“查看详情”->“资源UUID” |
- 如何安装/更新云监控客户端?
- 检查系统上签名文件是否存在:
# 是否存在
file /etc/sensecore/uuid.jwt
# 如果签名文件不存在,请联系裸金属技术支持生成
- 【ubuntu】安装并启动云监控客户端
# 卸载老版本
dpkg -l |grep -q sensecore-telemetry-bms && dpkg -r sensecore-telemetry-bms
# 安装并运行
wget https://bms-monitor.aoss.cn-sh-01.sensecoreapi-oss.cn/monitor/latest/sensecore-telemetry-bms.deb -O /tmp/sensecore-telemetry-bms.deb
dpkg -i --force-overwrite /tmp/sensecore-telemetry-bms.deb
rm -rf /tmp/sensecore-telemetry-bms.deb
# 检查服务是否正常
systemctl is-active sensecore-telemetry-bms
- 【rocky】安装并启动云监控客户端
# 卸载老版本
rpm -qa |grep -q sensecore-telemetry-bms && rpm -e --nodeps sensecore-telemetry-bms
# 安装并运行
wget https://bms-monitor.aoss.cn-sh-01.sensecoreapi-oss.cn/monitor/latest/sensecore-telemetry-bms.rpm -O /tmp/sensecore-telemetry-bms.rpm
rpm -ivh --force /tmp/sensecore-telemetry-bms.rpm
rm -rf /tmp/sensecore-telemetry-bms.rpm
# 检查服务是否正常
systemctl is-active sensecore-telemetry-bms
已交付节点启用 VNC 功能有哪些问题
ironic 多副本版本发布时,一并发布了console interface 的功能。在多副本版本之前注册的 Node 没有配置console_interfac,多副本版本之后注册的节点默认配置了ipmitool-socat。
多副本之前注册的节点
$ bm node show dfd37739-5f28-4e85-ade6-91c3014d6f8b --column console_interface
多副本之后注册的节点
$ bm node show acebeab3-a3d4-4cc3-95ac-ede785395723 --column console_interface
多副本版本之前注册,且已经交付的节点,启用 VNC 功能,需要解决如下问题:
BIOS 配置
具体BIOS具体看。
节点更新console_interface
本操作不会中断节点业务,但也建议和 BIOS 配置一起做。
- active 节点
# operator 会调协 unset maintenance
bm node maintenance set <NODD_UUID>
bm node set <NODD_UUID> --console-interface ipmitool-socat
bm node maintenance unset <NODD_UUID>
- available 节点
bm node set <NODD_UUID> --console-interface ipmitool-socat
使用Ubuntu 20.04 镜像的已交付节点,更新内核参数并重启
# 切换至 root 用户执行,需要重启
rm -rf /etc/default/grub.d
grub-mkconfig -o /boot/grub/grub.cfg
grub-mkconfig -o /boot/efi/EFI/ubuntu/grub.cfg
reboot
建议操作顺序
- 对于使用Ubuntu20.04 系统的用户,告知其更新内核参数并重启
- 配置console_interface
- 配置 BIOS
OFED驱动
OFED驱动卸载
[root@real-46 ~]# ofed_info -s
MLNX_OFED_LINUX-5.6-2.0.9.0:
文件上传:yeanhua ➜ scp -P 9004 MLNX_OFED_LINUX-5.6-2.0.9.0-rhel8.6-x86_64.tgz root@47.113.76.75:/root/
# cd /tmp && wget http://eyes.sensetime.com:9999/IB/MLNX_OFED_LINUX-5.6-2.0.9.0-rhel8.6-x86_64.tgz
cd /root/
tar -zxvf MLNX_OFED_LINUX-5.6-2.0.9.0-rhel8.6-x86_64.tgz
cd MLNX_OFED_LINUX-5.6-2.0.9.0-rhel8.6-x86_64/ && ./uninstall.sh --force -q
reboot
# 删除ofed驱动后bond1依然可以ping通
6: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 10:70:fd:6d:d7:5a brd ff:ff:ff:ff:ff:ff
inet 10.119.241.172/27 brd 10.119.241.191 scope global noprefixroute bond1
valid_lft forever preferred_lft forever
inet6 fe80::1270:fdff:fe6d:d75a/64 scope link
valid_lft forever preferred_lft forever
[root@real-46 ~]# ping -c 2 10.119.241.172
PING 10.119.241.172 (10.119.241.172) 56(84) bytes of data.
64 bytes from 10.119.241.172: icmp_seq=1 ttl=64 time=0.013 ms
64 bytes from 10.119.241.172: icmp_seq=2 ttl=64 time=0.011 ms
--- 10.119.241.172 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1024ms
rtt min/avg/max/mdev = 0.011/0.012/0.013/0.001 ms
OFED驱动重装
# 以下适用【GPU实例 CPU实例】
# cd /root && wget http://eyes.sensetime.com:9999/IB/MLNX_OFED_LINUX-5.8-1.1.2.1-rhel8.6-x86_64.tgz
# 本地上传,本地的tgz包可以下载自上面链接
scp -P 9004 ./MLNX_OFED_LINUX-5.8-1.1.2.1-rhel8.6-x86_64.tgz root@47.113.76.75:/root/
cd /root/ && tar -zxvf MLNX_OFED_LINUX-5.8-1.1.2.1-rhel8.6-x86_64.tgz
yum install tk gcc-gfortran tcsh kernel-rpm-macros python36-devel -y
yum install kernel-rpm-macros python36-devel kernel-devel-4.18.0-425.3.1.el8.x86_64 kernel-headers.x86_64 kernel-tools.x86_64 kernel-tools-libs.x86_64 -y --allowerasing
注:kernel-tools-libs-devel-4.18.0-425.3.1.el8.x86_64 这个包会被remove掉
cd /root/MLNX_OFED_LINUX-5.8-1.1.2.1-rhel8.6-x86_64 && ./mlnxofedinstall --add-kernel-support --skip-repo --force
systemctl enable openibd
# 完成后重启系统: 重启后可以看到openibd服务是active的状态
reboot
[root@real-46 ~]# systemctl is-active openibd
active
# 查看ofed驱动版本命令并确认与前面的安装包文件中的版本号一致
[root@real-46 ~]# ofed_info -s
MLNX_OFED_LINUX-5.8-1.1.2.1:
# 验证ib状态以及roce操作是否正常: 通过
roce连通性 - 网关:确保ping成功
ping -c 2 10.119.241.161
roce连通性 - 双机ib_read_lat:确保执行成功
server: [root@real-46 ~]# ib_read_lat
client: [root@real-119 ~]# ib_read_lat -d mlx5_1 -a --report_gbits 10.119.241.172
GPU驱动
GPU驱动卸载
[root@real-46 ~]# systemctl stop nvidia-fabricmanager
[root@real-46 ~]# nvidia-uninstall -q -s
WARNING: Your driver installation has been altered since it was initially installed; this may happen, for example, if you have since installed the NVIDIA driver through a mechanism other than nvidia-installer (such as your
distribution's native package management system). nvidia-installer will attempt to uninstall as best it can. Please see the file '/var/log/nvidia-uninstall.log' for details.
GPU驱动重装
# 安装GPU驱动
# cd /tmp/ && wget http://eyes.sensetime.com:9999/IB/gpu_driver_new/NVIDIA-Linux-x86_64-515.65.01.run
scp -P 9004 ./NVIDIA-Linux-x86_64-515.65.01.run root@47.113.76.75:/tmp/
cd /tmp/ && chmod +x NVIDIA-Linux-x86_64-515.65.01.run
# NVIDIA-Linux-x86_64-515.65.01.run需要执行权限
cd /tmp && ./NVIDIA-Linux-x86_64-515.65.01.run -a -s -Z
# 如以上安装方法出现报错使用以下方法安装
cd /tmp && ./NVIDIA-Linux-x86_64-515.65.01.run --kernel-source-path /usr/src/kernels/4.18.0-425.3.1.el8.x86_64
# 一次性设置pm模式正常
/usr/bin/nvidia-smi -pm 1
# 启动fm
systemctl restart nvidia-fabricmanager
# 按需调整/etc/rc.local重启查看pm效果
# pm设置有效,查看方式:
nvidia-smi
# 验证cuda功能
参考:https://sco-aiiaas.feishu.cn/wiki/wikcnvTScTIY01IJjmErSHEDT1u
git clone https://github.com/NVIDIA/cuda-samples.git
cd cuda-samples
make -j
# 对于A100,可以使用 make -j SMS="80"
# 进入到编译成功后的bin/..../release下执行以下用例
cd bin/x86_64/linux/release/
[root@localhost release]# ./vectorAdd
[Vector addition of 50000 elements]
Failed to allocate device vector A (error code system not yet initialized)!
[root@localhost release]# ./deviceQuery
# mig设置:成功
参考:https://sco-aiiaas.feishu.cn/wiki/wikcnqaNHEXrVVOucJkwAhoPXfi
# 打开执行成功
[root@real-46 release]# nvidia-smi -mig 1
# 关闭执行成功
[root@real-46 release]# nvidia-smi -mig 0