语音合成-音色融合WebSocket
接口描述(Description)
该 API 提供基于文本到语音(Text-to-Speech, TTS)的同步语音合成功能。
请求地址(Request URL)
[POST] wss://api.sensenova.cn/v1/audio/ws/speech_fusion
请求头(Request Header)
在请求头中,添加 Authorization 字段,生成 API Key,如下所示:
HEADERS = {
"Authorization": "Bearer {API_KEY}" //$API_KEY 在大装置万象模型平台ModelStudio中服务管理获取
}
接口调用时序图
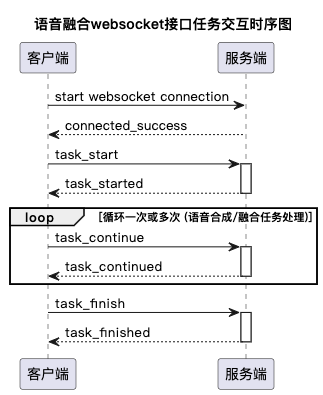
开始事件(task_start)
请求参数
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| event | string | 是 | 无 | 在开始请求时使用task_start,在持续进行请求时使用task_continue,结束请求时使用task_finish |
| model | string | 是 | 无 | 模型名称: 用于指定语音合成所采用的模型, 当前为 SenseNova-Audio-Fusion-0603。 |
| voice_setting | object | 是 | 无 | 声音设置 |
| audio_setting | object | 是 | 无 | 音频格式设置 |
| timbre_weights | object | 否 | 无 | 融合音色权重 (音色名称: 权重值): 用于自定义混合多种音色的合成效果。各音色的权重值总和建议为 1.0, voice 参数指定的主音色必须包含在该权重列表中。支持最多不超过 4 款音色融合。 |
voice_setting参数如下:
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| voice | string | 是 | 无 | 主音色名称: 用于指定语音合成时的主要音色, 详见音色列表, 在使用融合音色功能时, 该音色也必须包含在 timbre_weights 中。 |
| speed | float | 否 | 1 | 语速: 用于设置语音的播放速度, 取值范围为 [0.5, 2.0]。其中, 1.0 表示正常语速, 数值越小语速越慢, 数值越大语速越快。 |
| volume | float | 否 | 1 | 音量: 用于调节合成语音的响度, 取值范围为 (0, 10], 值越大音量越高。 |
| pitch | int | 否 | 0 | 音调: 用于控制合成语音的音高, 取值范围为整数 [-12, 12]。其中, 0 表示保持原始音调, 正值提高音调, 负值降低音调。 |
audio_setting参数如下:
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| sample_rate | int | 否 | 32000 | 音频采样率, 取值范围 [8000, 16000, 22050, 24000, 32000, 44100] |
| channel | int | 否 | 2 | 音频声道, 支持单声道 1, 双声道 2 |
| bitrate | int | 否 | 128000 | 音频码率, 支持 MP3, 取值范围 [32000, 64000, 128000, 256000] |
| response_format | string | 否 | mp3 | 输出结果格式: 可选值 mp3、wav、pcm。 |
timbre_weights参数如下:
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| voice | weight | 是 | 无 | 融合音色 |
| weight | float | 是 | (0, 1.0] | 融合音色权重 |
timbre_weights: 融合音色权重为空或不存在,默认是单音色。否则是融合音色。
voice可选音色如下:
| Voice ID | 名称 | 是否支持融合 |
|---|---|---|
| child_reqing | 热情孩童 | 是 |
| man_zhengqi | 正气中年 | 是 |
| man_weiyan | 威严霸总 | 是 |
| guy_qingshuang | 清爽帅哥 | 是 |
| guy_wenrun | 温润暖男 | 是 |
| male_shenqing | 深情男友 | 是 |
| male_miantian | 腼腆男友 | 是 |
| woman_daihuo | 带货女神 | 是 |
| female_chunzhen | 纯真少女 | 是 |
| female_jiaomei | 娇媚女友 | 是 |
| woman_fengyun | 风韵少妇 | 是 |
| man_qiangyu | 强欲霸总 | 是 |
| guy_shizun | 清冷师尊 | 是 |
| guy_nangong | 挚爱男攻 | 是 |
| female_taimei | 甜甜台妹 | 是 |
| guy_guimi | 男性闺蜜 | 是 |
| female_shumei | 熟媚女神 | 是 |
| man_nuanren | 暖人青叔 | 是 |
| guy_naigou1 | 贴心奶狗 | 是 |
| guy_xingui | 冷御新贵 | 是 |
| female_sajiao | 撒娇甜妹 | 是 |
| female_diantai | 电台女声 | 是 |
| female_diantai_b | 娇俏小妹 | 是 |
| female_jiejie | 明魅御姐 | 是 |
| female_jiejie_a | 爱欲女王 | 是 |
| female_jiejie_b | 柔情女王 | 是 |
| girl_banxia | 娇怜软妹 | 是 |
| girl_banxia_a | 破碎少女 | 是 |
| man_cucao | 冷面硬汉 | 是 |
| guy_xingui_b | 深情病娇 | 是 |
| guy_qiangai | 强爱病娇 | 是 |
| guy_shengse | 生涩奶狗 | 是 |
| female_jiaonv_a | 羞婉娇女 | 是 |
| female_ruanmei_a | 俏萌软妹 | 是 |
| oldman_zhangzhe | 威严长者 | 是 |
| woman_xiuse | 羞涩御姐 | 是 |
响应参数(Response Body)
connected_success:初次请求接口时,表示连接建立成功,此时会话未开始,无session_id
| 参数名 | 类型 | 说明 |
|---|---|---|
| event | string | 请求事件类型, 成功返回 connected_success |
| trace_id | string | 本次请求的唯一标识, 用于定位请求 |
task_started: 标志任务已成功开始
| 参数名 | 类型 | 说明 |
|---|---|---|
| event | string | 请求事件类型, 成功返回 task_started, 失败返回task_failed |
| trace_id | string | 本次请求的唯一标识, 用于定位请求 |
| session_id | string | 本次流式会话的唯一标识,仅在服务端返回task_starteds时该值不为空 |
继续事件(task_continued)
请求参数
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| event | string | 是 | 无 | 在开始请求时使用task_start,在持续进行请求时使用task_continue,结束请求时使用task_finish |
| input | string | 是 | 无 | 合成文本内容: 待转换为语音的文本信息, 支持中文及英文内容输入。 |
响应参数(Response Body)
| 参数名 | 类型 | 说明 |
|---|---|---|
| event | string | 请求事件类型 |
| data | object | 返回的音频数据,仅在is_final为false的数据包中包含音频数据 |
| trace_id | string | 本次请求的唯一标识, 用于定位请求 |
| session_id | string | 本次流式会话的唯一标识,仅在服务端返回task_starteds时该值不为空 |
| is_final | bool | 是否结束 |
| extra_ino | object | 扩展信息,is_final为true的消息包含usage信息 |
data参数如下:
| 参数名 | 类型 | 说明 |
|---|---|---|
| audio | string | 音频数据内容或者音频文件 url, 由 output_format 决定 |
| status | int | 当前音频流状态: 1 表示合成中, 2 表示合成结束 |
extra_info参数如下:
| 参数名 | 类型 | 说明 |
|---|---|---|
| length | int | 音频时长, 单位毫秒 |
| size | int | 音频文件大小 |
| sample_rate | int | 音频采样率 |
| bitrate | float | 音频码率, 支持 MP3 |
| channel | int | 音频声道, 支持单声道 1, 双声道 2 |
| response_format | string | 输出结果格式: 可选值 mp3、wav、pcm |
| usage_characters | int | 计费字符数 |
| word_count | int | 已发音的字符数 |
结束事件(task_finish)
请求参数
| 参数名 | 类型 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|---|
| event | string | 是 | 无 | 在开始请求时使用task_start,在持续进行请求时使用task_continue,结束请求时使用task_finish |
响应参数(Response Body)
task_finished: 标志任务已结束
| 参数名 | 类型 | 说明 |
|---|---|---|
| event | string | 请求事件类型 |
| trace_id | string | 本次请求的唯一标识, 用于定位请求 |
| session_id | string | 本次流式会话的唯一标识,仅在服务端返回task_starteds时该值不为空 |
当最后一次收到服务端返回结果后超过 120s 没有发送新事件时 webSocket 连接自动断开。
task_failed: 标志任务失败
| 参数名 | 类型 | 说明 |
|---|---|---|
| event | string | 请求事件类型 |
| trace_id | string | 本次请求的唯一标识, 用于定位请求 |
| session_id | string | 本次流式会话的唯一标识,仅在服务端返回task_starteds时该值不为空 |
| error_msg | string | 失败message信息 |
请求示例(Request Example)
Python 示例
import websocket
import json
import base64
import threading
import time
class SpeechFusionClient:
def __init__(self, api_key):
self.api_key = api_key
self.ws_url = "wss://api.sensenova.cn/v1/audio/ws/speech_fusion"
self.ws = None
self.session_id = None
self.trace_id = None
def on_message(self, ws, message):
"""处理服务器返回的消息"""
try:
data = json.loads(message)
event_type = data.get("event")
print(f"收到消息 - 事件类型: {event_type}")
print(f"Trace ID: {data.get('trace_id')}")
if event_type == "task_started":
self.session_id = data.get("session_id")
print(f"会话建立成功,Session ID: {self.session_id}")
elif event_type == "audio_data":
# 处理音频数据
audio_data = data.get("data", {})
audio_content = audio_data.get("audio")
status = audio_data.get("status")
if audio_content and status == 1:
# 解码base64音频数据(如果是base64格式)
try:
audio_bytes = base64.b64decode(audio_content)
print(f"收到音频数据,长度: {len(audio_bytes)} 字节")
# 这里可以保存或处理音频数据
# with open("output_audio.mp3", "wb") as f:
# f.write(audio_bytes)
except:
print(f"收到音频URL或数据: {audio_content}")
if data.get("is_final"):
extra_info = data.get("extra_info", {})
print(f"合成完成 - 时长: {extra_info.get('length')}ms, 字符数: {extra_info.get('word_count')}")
elif event_type == "task_failed":
print(f"任务失败: {data}")
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
print(f"原始消息: {message}")
def on_error(self, ws, error):
"""处理错误"""
print(f"WebSocket错误: {error}")
def on_close(self, ws, close_status_code, close_msg):
"""连接关闭"""
print("WebSocket连接已关闭")
def on_open(self, ws):
"""连接建立后发送开始事件"""
print("WebSocket连接已建立")
self.send_start_event()
def send_start_event(self):
"""发送开始事件"""
start_data = {
"event": "task_start",
"model": "SenseNova-Audio-Fusion-0603",
"voice_setting": {
"voice": "female_jiejie",
"speed": 1.0,
"volume": 1.0,
"pitch": 0
},
"audio_setting": {
"sample_rate": 32000,
"channel": 2,
"bitrate": 128000,
"response_format": "mp3"
},
"timbre_weights": {
"female_jiejie": 0.7,
"female_diantai": 0.3
}
}
self.send_message(start_data)
def send_continue_event(self, text):
"""发送继续事件(文本合成)"""
continue_data = {
"event": "task_continue",
"input": text
}
self.send_message(continue_data)
def send_finish_event(self):
"""发送结束事件"""
finish_data = {
"event": "task_finish"
}
self.send_message(finish_data)
def send_message(self, data):
"""发送消息到服务器"""
if self.ws and self.ws.sock and self.ws.sock.connected:
message = json.dumps(data)
self.ws.send(message)
print(f"已发送: {data['event']}")
else:
print("WebSocket未连接")
def connect(self):
"""建立WebSocket连接"""
headers = {
"Authorization": f"Bearer {self.api_key}"
}
self.ws = websocket.WebSocketApp(
self.ws_url,
header=headers,
on_message=self.on_message,
on_error=self.on_error,
on_close=self.on_close,
on_open=self.on_open
)
# 运行WebSocket客户端
self.ws.run_forever()
def synthesize_speech(self, text):
"""合成语音的完整流程"""
def run_synthesis():
# 等待连接建立
time.sleep(2)
# 发送文本进行合成
self.send_continue_event(text)
# 等待合成完成
time.sleep(5)
# 发送结束事件
self.send_finish_event()
# 等待一会后关闭连接
time.sleep(2)
self.ws.close()
# 在新线程中运行合成流程
synthesis_thread = threading.Thread(target=run_synthesis)
synthesis_thread.start()
# 使用示例
if __name__ == "__main__":
# 替换为您的实际API Key
API_KEY = "your_api_key_here"
# 创建客户端实例
client = SpeechFusionClient(API_KEY)
# 要合成的文本
text_to_synthesize = "大家好,这是一个语音合成测试示例。欢迎使用语音音色融合功能。"
try:
# 连接并合成语音
client.connect()
# 或者使用完整的合成流程
# client.synthesize_speech(text_to_synthesize)
except KeyboardInterrupt:
print("用户中断程序")
except Exception as e:
print(f"程序错误: {e}")