【NGC 镜像】nccl-test 通信库检测最佳实践
前置准备工作
- 资源配置需要区分当前是单机检测还是多机检测,副本数对应1或者n。
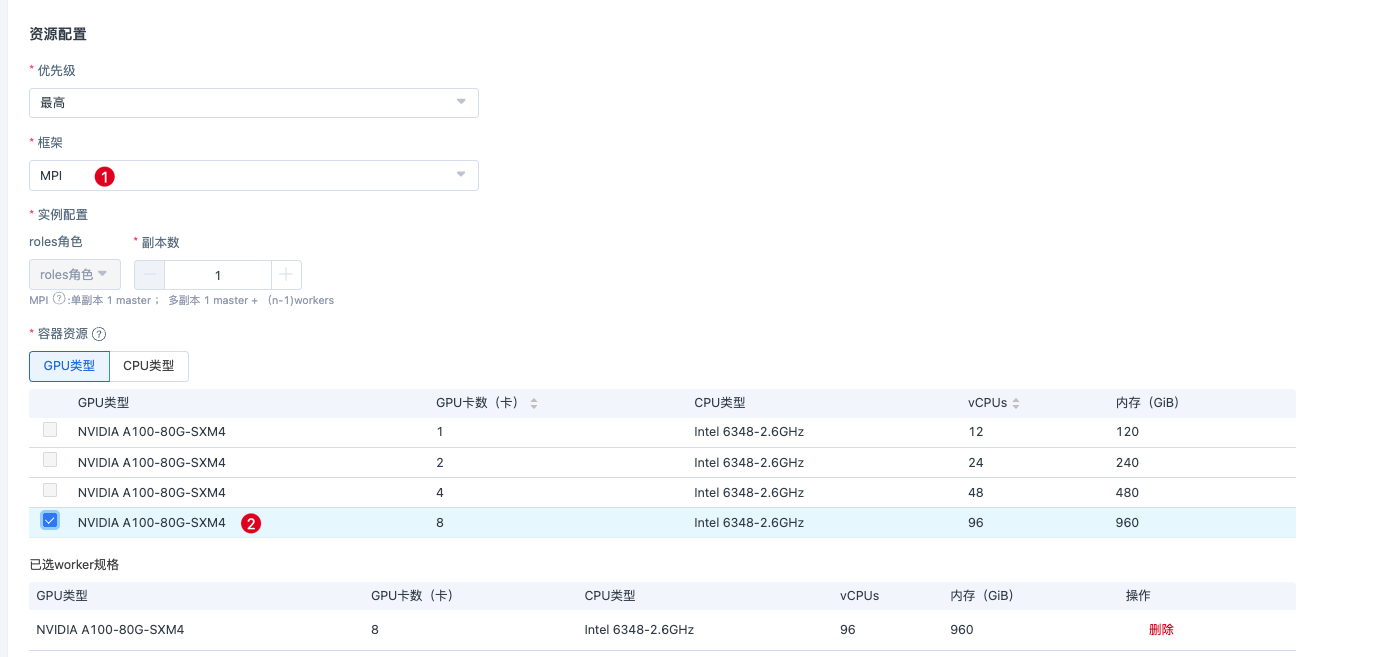
- 为了达到最佳性能测试结果,不同的网络集群方案需要注入不同的环境变量,详情参考通用环境变量。
例如在RoCE v2 *400G网络方案下,点击【高级配置】,配置以下环境变量:
NCCL_IB_GID_INDEX = 5
NCCL_IB_TC = 138
NCCL_IB_QPS_PER_CONNECTION = 8
OMPI_MCA_btl_tcp_if_include = eth0
补充说明:
如果通过nccl-test做集群网络的基线测试,可以设置NCCL_MIN_NCHANNELS=32,可以大幅度提高测试结果,这个参数用于 优化 NCCL 通信并发度 的环境变量设置,控制 NCCL 内部用于并发通信的数据通道(channel)的 最小数量。不过在实际训练过程中,通信用的资源多,计算可用资源就会变少,用户要根据实际情况做调整。

- 启动命令写成
sleep inf,让容器保持长运行状态,方便执行相关的检测脚本。

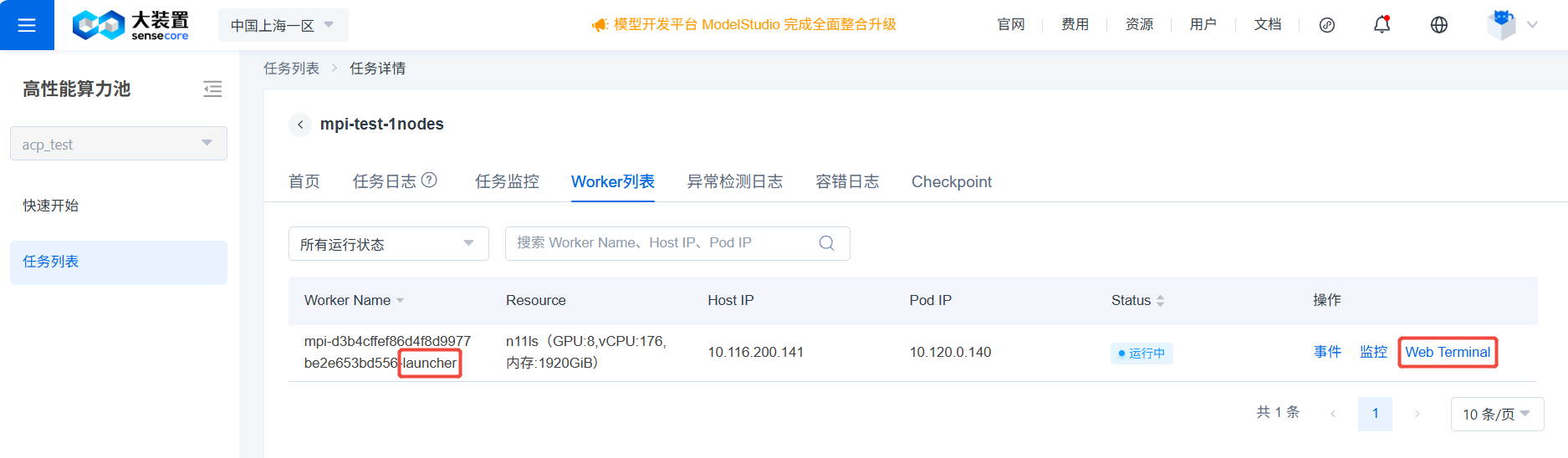
- 通过【Web Terminal】登录到 pod ,注意选择名称含 launcher 的 Worker。
- 输入
ldconfig -p | grep libnccl.so,检查系统中NCCL 库安装路径及版本信息。

- 输入
ll /usr/lib/x86_64-linux-gnu/libnccl.so*,查看 NCCL 库文件的详细信息,包括符号链接关系和版本号。

- 输入
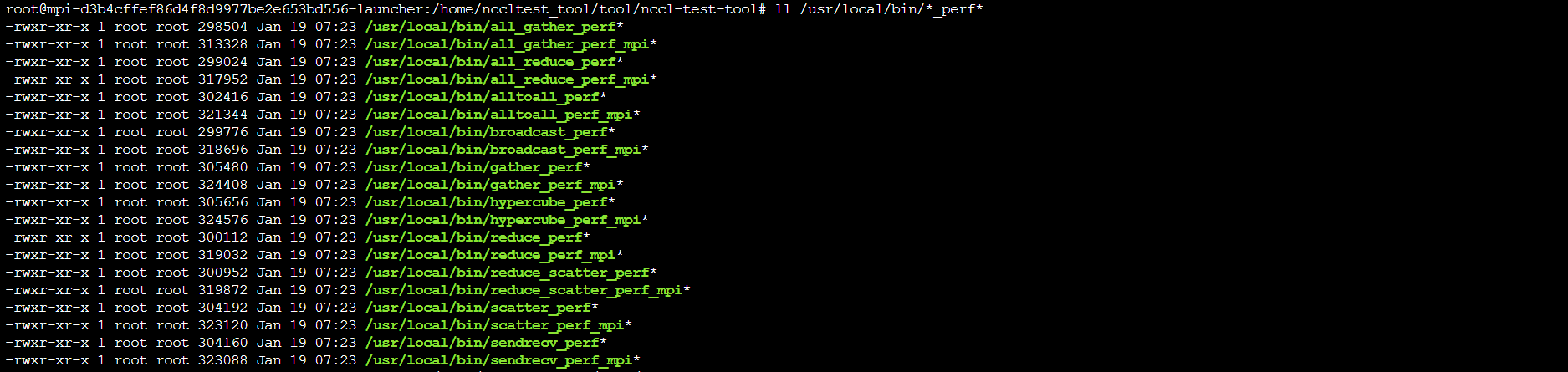
ll /usr/local/bin/*_perf*,查看系统中与性能测试相关的工具。
注意:MPI任务必须使用后缀为 _mpi 的命令。
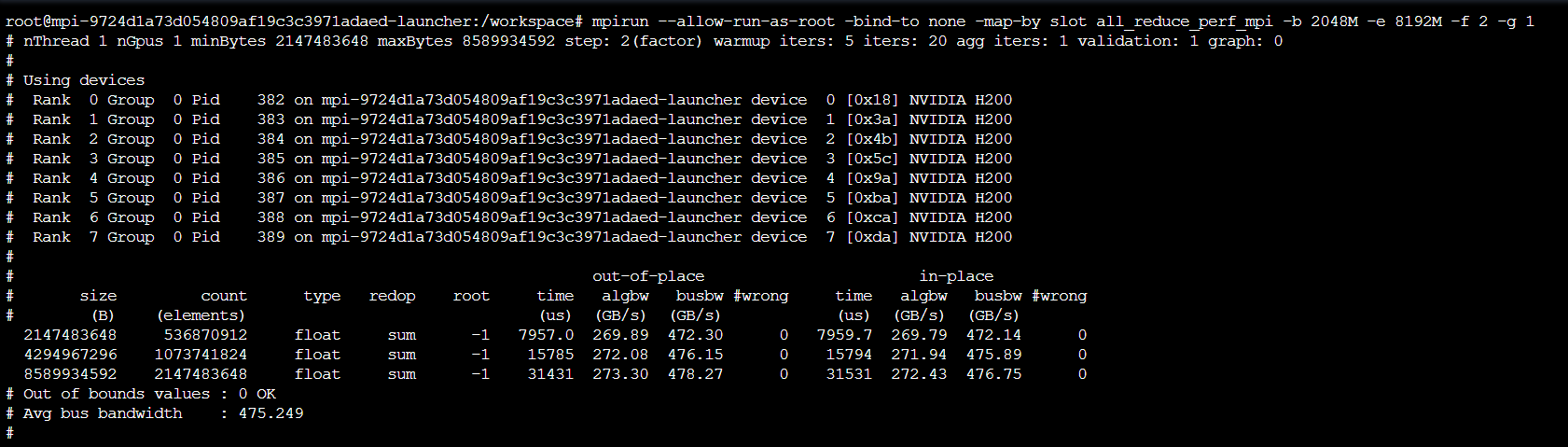
MPI任务_单机通信库检测(1副本)
注:单机1副本8卡,np为1*8,8个进程。
操作指令:mpirun --allow-run-as-root -bind-to none -map-by slot all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
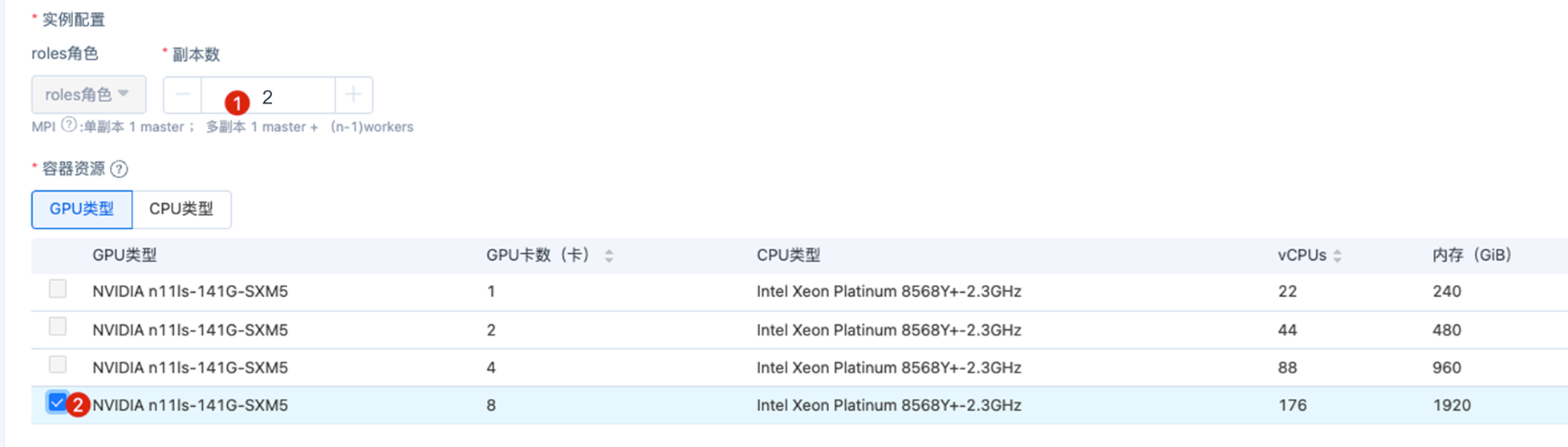
MPI任务_多机通信库检测(2副本)
注:多机2副本16卡,np为2*8,16个进程。
通过 nccl-test 检测2*8卡的集合通信的情况,副本数设置为2,选择8卡的产品规格。
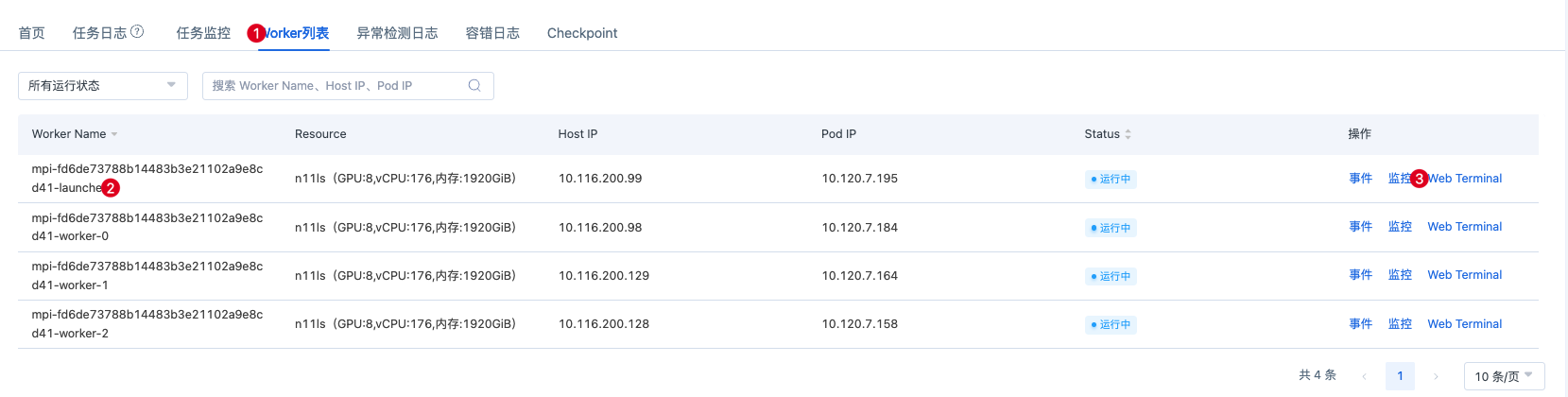
任务创建好后,在【任务详情】页的【Worker列表】tab页,通过【Web Terminal】登录到pod ,注意选择名称含 launcher 的 Worker。
操作指令:mpirun --allow-run-as-root -bind-to none -map-by slot --mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" -mca pml ob1 -mca btl ^openib -mca plm_rsh_num_concurrent 300 -mca routed_radix 600 -mca plm_rsh_no_tree_spawn 1 all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
2台的测试结果如下:
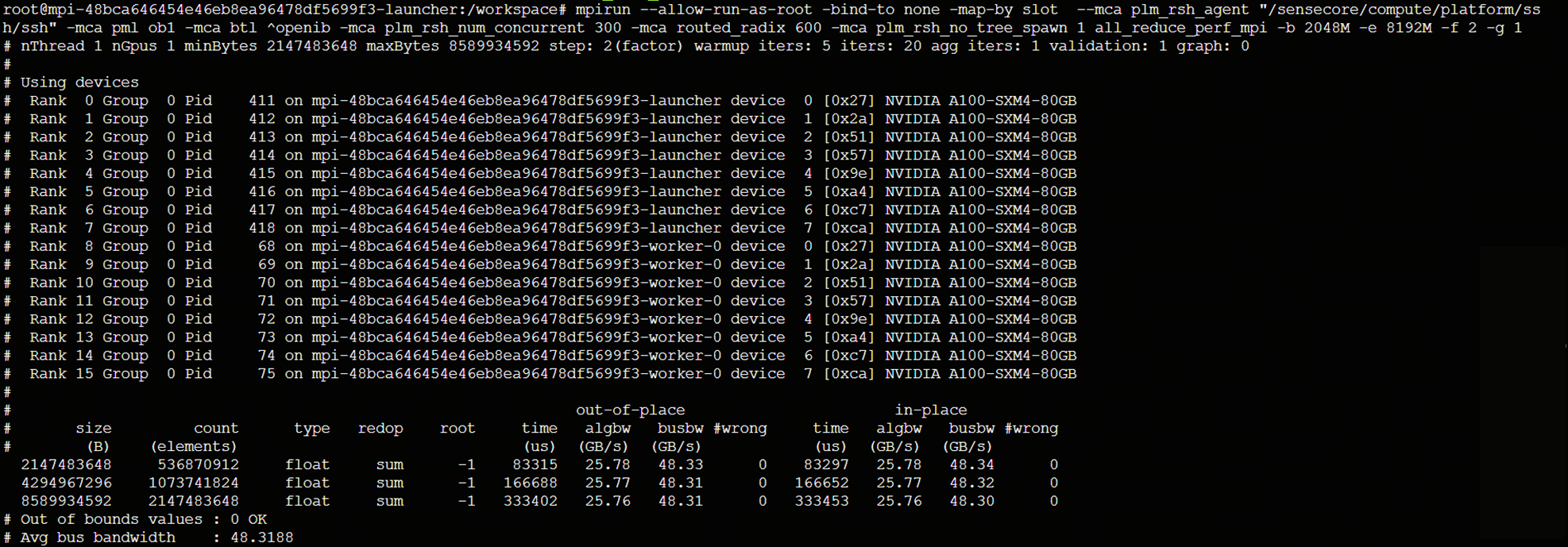
测试结果解读
详情可查阅官方文档:https://github.com/NVIDIA/nccl-tests
- 数据规模:
size:操作处理的数据的大小,以字节为单位。
count:操作处理的元素的数量。count 越大,对总线带宽、网络带宽的需求越高。
type:元素的数据类型。
redop:使用的归约操作。
root:对于某些操作(如 reduce 和 broadcast),这列指定了根节点的编号。-1表示这个操作没有根节点(因为 all-reduce 操作涉及所有节点)。
- 通信类型:
out-of-place:操作结果存储在新分配的内存区域,需将原数据复制到新位置。
in-place:直接在原内存地址上修改数据,无需额外内存分配。
- 性能指标:
注意:各个指标均为对应数据大小size下,20 次迭代(iters=20)结果的平均值,迭代次数可通过-n参数调整。
time (us):单次操作从开始到结束的耗时。
algbw (GB/s):算法实际达到的数据传输带宽。
busbw (GB/s):总线带宽(理论峰值)。
#wrong:错误数(若非0,可能表示有一些错误发生)。
Avg bus bandwidth:平均总线带宽。
如何修改hostfile
新建一个8副本,每个副本4张GPU卡任务,总共有8*4=32张卡,执行如下命令,会看到rank 0 ~ rank31的设备信息。
mpirun --allow-run-as-root -bind-to none -map-by slot --mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" -mca pml ob1 -mca btl ^openib -mca plm_rsh_num_concurrent 300 -mca routed_radix 600 -mca plm_rsh_no_tree_spawn 1 all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
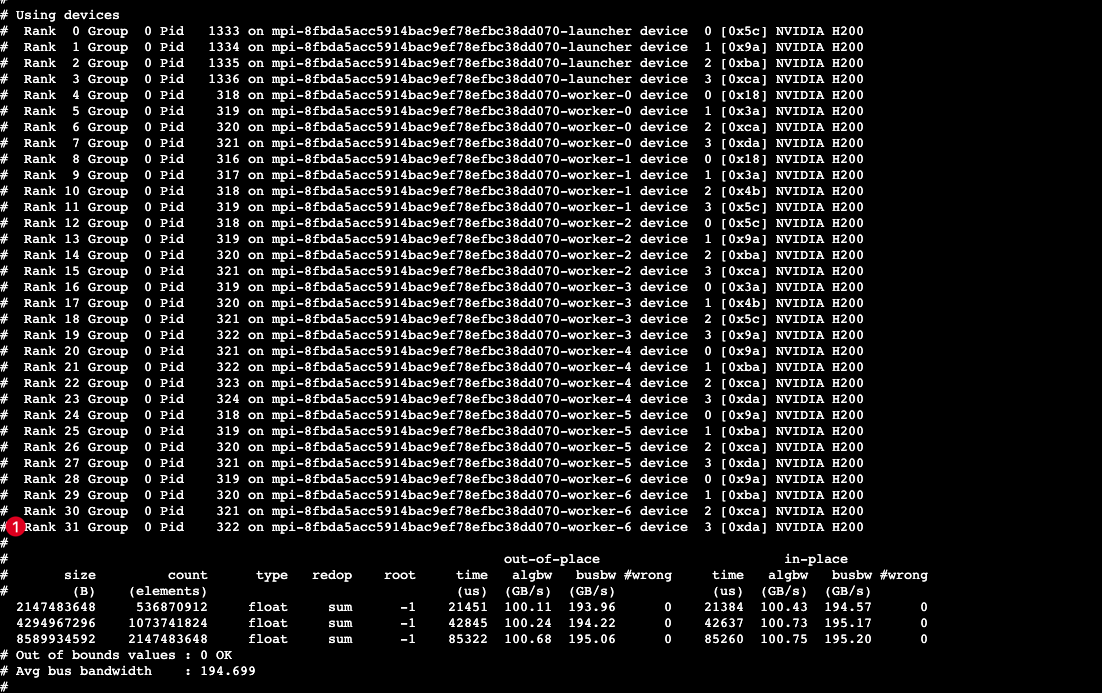
mpirun默认的hostfile文件位置为/etc/mpi/hostfile,如果想要修改节点对应的hostip或者指定节点测试(比如8副本的任务,指定其中4个节点或者指定异常节点。
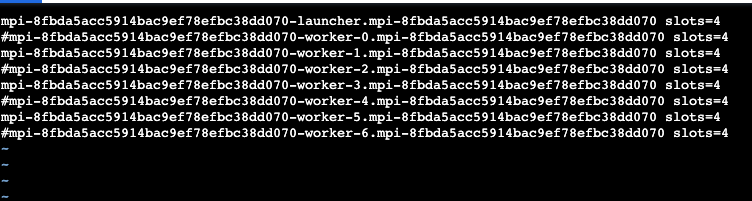
因为官方的/etc/mpi/hostfile 为read only,复制一份hostfile进行编辑:mkdir /etc/nccl-test && cat /etc/mpi/hostfile > /etc/nccl-test/mpihostfile ,然后执行:vim /etc/nccl-test/mpihostfile 。注释掉2、4、6、8行,如 下图所示,这时跑测试只有4*4=16个GPU参与测试。
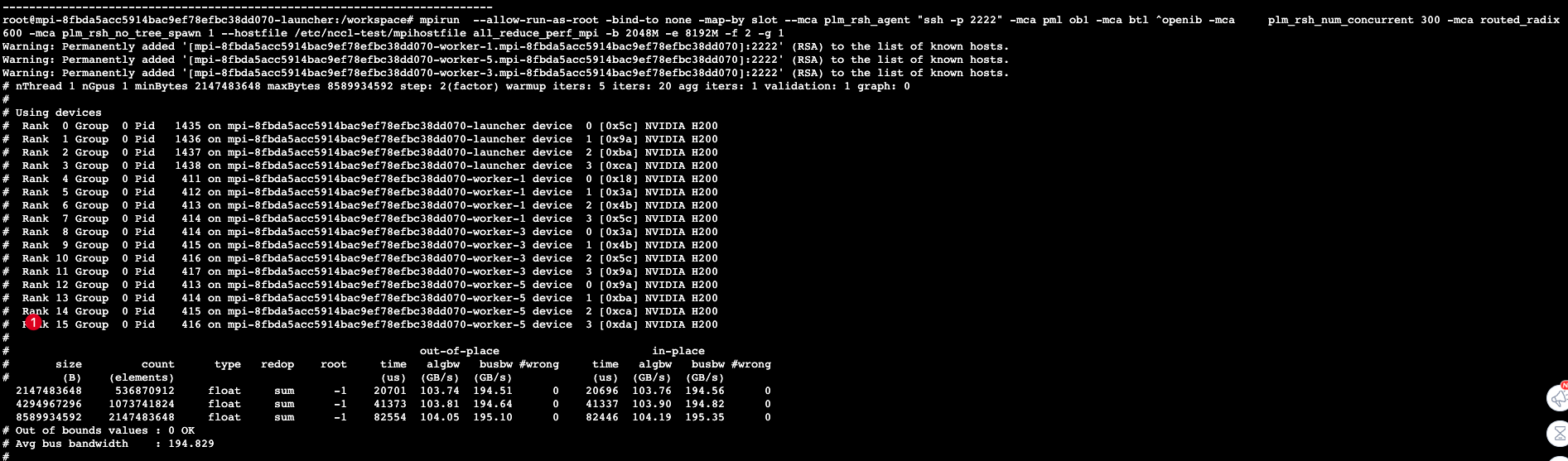
指定其他位置的hostfile可使用--hostfile参数,示例为:--hostfile /etc/nccl-test/mpihostfile。执行如下命令,会看到rank 0 ~ rank15的设备信息。
mpirun --allow-run-as-root -bind-to none -map-by slot --mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" -mca pml ob1 -mca btl ^openib -mca plm_rsh_num_concurrent 300 -mca routed_radix 600 -mca plm_rsh_no_tree_spawn 1 --hostfile /etc/nccl-test/mpihostfile all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
操作命令解释
| 操作指令 | 解释 | 备注 | ||
|---|---|---|---|---|
| ldconfig -p | grep libnccl.so | 检查系统中是否已安装 NCCL 库 以及其版本信息 | |||
| ll /usr/lib/x86_64-linux-gnu/libnccl.so* | 查看 NCCL 库文件的详细信息,包括符号链接关系和版本号 | |||
| ll /usr/local/bin/*_perf* | 查看系统中与性能测试相关的工具。每个文件对应一种集体通信操作,用于测试特定操作的带宽、延迟等指标 | 该命令结果说明见后表 | ||
| --hostfile /etc/mpi/hostfile | 指定主机文件路径 | 节点与进程配置 | ||
| --allow-run-as-root | 允许以 root 用户身份运行 MPI 任务 | |||
| -np 16 | 指定要运行的进程数,应与要使用的总 GPU 数量相匹配。如 2 个副本,每台有 8 个 GPU,则为-np 16 | |||
| -bind-to none | 不将进程绑定到特定 CPU,亲和性设置为none,可以去掉 | 进程绑定与映射策略 | ||
| -map-by slot | 表示任务会按照 slot 的顺序分配到节点上 | |||
| --mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" | 使用平台默认的SSH路径通信 | 底层通信库配置(MCA 参数) | ||
| -mca pml ob1 | 使用OpenMPI BTL作为消息传递层 | |||
| -mca btl ^openib | 禁用 InfiniBand 网络(使用以太网替代) | |||
| -mca plm_rsh_num_concurrent 300 | 允许 300 个并发 SSH 连接 | |||
| -mca routed_radix 600 | 路由基数设置为 600(影响大规模集群通信拓扑) | |||
| -mca plm_rsh_no_tree_spawn 1 | 禁用树形 Spawn 优化(适用于特殊网络环境) | |||
| -b 2048M | 最小测试数据量为 2048MB(2GB) | 性能测试参数 | ||
| -e 8192M | 最大测试数据量为 8192MB(8GB) | |||
| -f 2 | 数据量按 2 的幂次递增(2GB → 4GB → 8GB) | |||
| -g 1 | 每个进程使用 1 个 GPU | |||
ll /usr/local/bin/*_perf*命令结果说明:
| 文件名 | 测试的通信操作 | 说明 |
|---|---|---|
| all_gather_perf | 全收集(AllGather) | 该操作中,每个节点都有一个值,这些值被收集到一个列表中,然后这个列表被发送回所有的节点。 |
| all_reduce_perf | 归约后广播(AllReduce) | 该操作中,所有的节点都有一个输入值,这些值被归约(如求和或求最大值)为一个单一值,然后该值被发送回所有的节点。 |
| alltoall_perf | 全交换(AllToAll) | 该操作中,每个节点都发送一个值给所有其他的节点,并从所有其他的节点接收一个值。 |
| broadcast_perf | 广播(Broadcast) | 该操作中,每个节点有一个值,然后这个值被发送到所有其他的节点。 |
| gather_perf | 收集(Gather) | 该操作中,每个节点都有一个值,这些值被收集到一个列表中,然后该列表被发送到一个指定的节点。 |
| reduce_perf | 归约(Reduce) | 该操作中,所有节点都有一个输入值,这些值被归约成一个单一的值,然后该值被发送到一个指定的节点。 |
| reduce_scatter_perf | 归约散射(ReduceScatter) | 该操作中,所有节点都有一个输入值,这些值被归约成一个单一的值,然后这个值被分散到所有的节点。 |
| scatter_perf | 散射(Scatter) | 该操作中,一个节点有一个列表的值,然后这些值被分散到所有其他的节点。 |
| sendrecv_perf | 点对点发送接收(Send/Recv) | 该操作中,一个节点有一个包含多个值的列表,然后其中的值被分散到所有其他的节点。 |
| hypercube_perf | 超立方体通信 | 在 hypercube通信模式中,节点被组织成一个超立方体的结构,然后在这个结构中进行通信。 |
单机操作指令补充说明:
单机情况下,不需要添加与多机相关的特定指令参数,样例如下:
mpirun --allow-run-as-root -bind-to none -map-by slot all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
去除与多机相关的特定参数-mac:
像--mca plm_rsh_agent这类用于多机间通过 SSH 等方式通信的参数,单机测试时可去除,因为无需跨机通信。还有-mca plm_rsh_num_concurrent、-mca routed_radix、-mca plm_rsh_no_tree_spawn等与多机资源调度和远程 Shell 相关参数,一般也可删除。