创建任务
基本信息
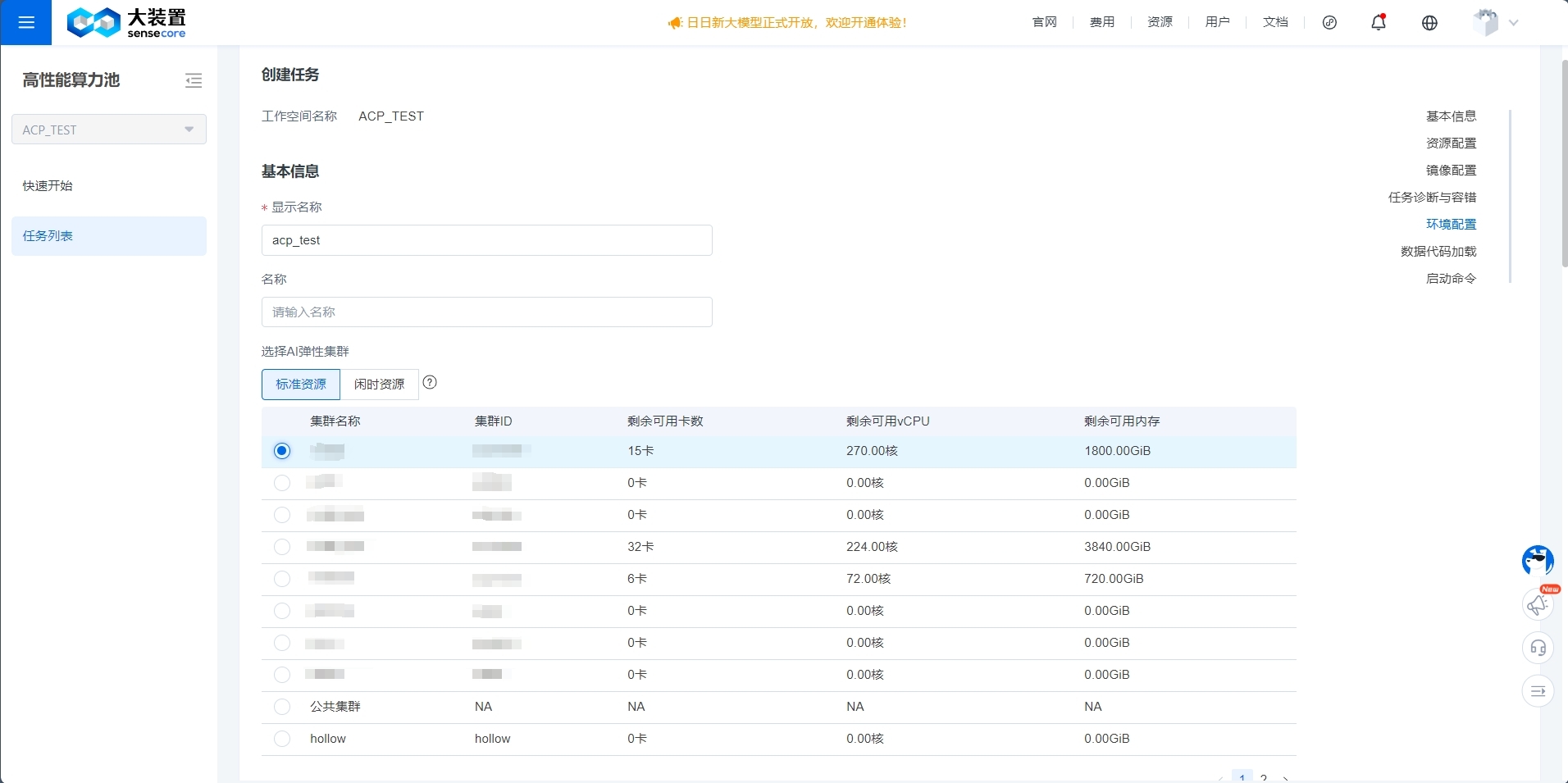
- 工作空间:支持用户从创建好的工作空间中选择一个,或者新建workspace;
- 显示名称:支持自定义任务的显示名称;
- 名称:支持自定义名称(如果客户未填写,平台将自动生成,每个任务的名称在工作空间下确保唯一);
- AI弹性集群:算力池的训练任务必须基于工作空间,且只能使用工作空间所关联的集群下的节点,因此这里需要选择使用某个集群的资源。其中有不同的资源类型:标准资源-专属集群、标准资源-公共集群、闲时资源;用户可在弹性集群中按需购买对应资源;
- 地区和可用区 & VPC:针对标准资源-公共集群和闲时资源,根据购买区域资源需要选择地区和可用区,以及配置VPC。
资源配置
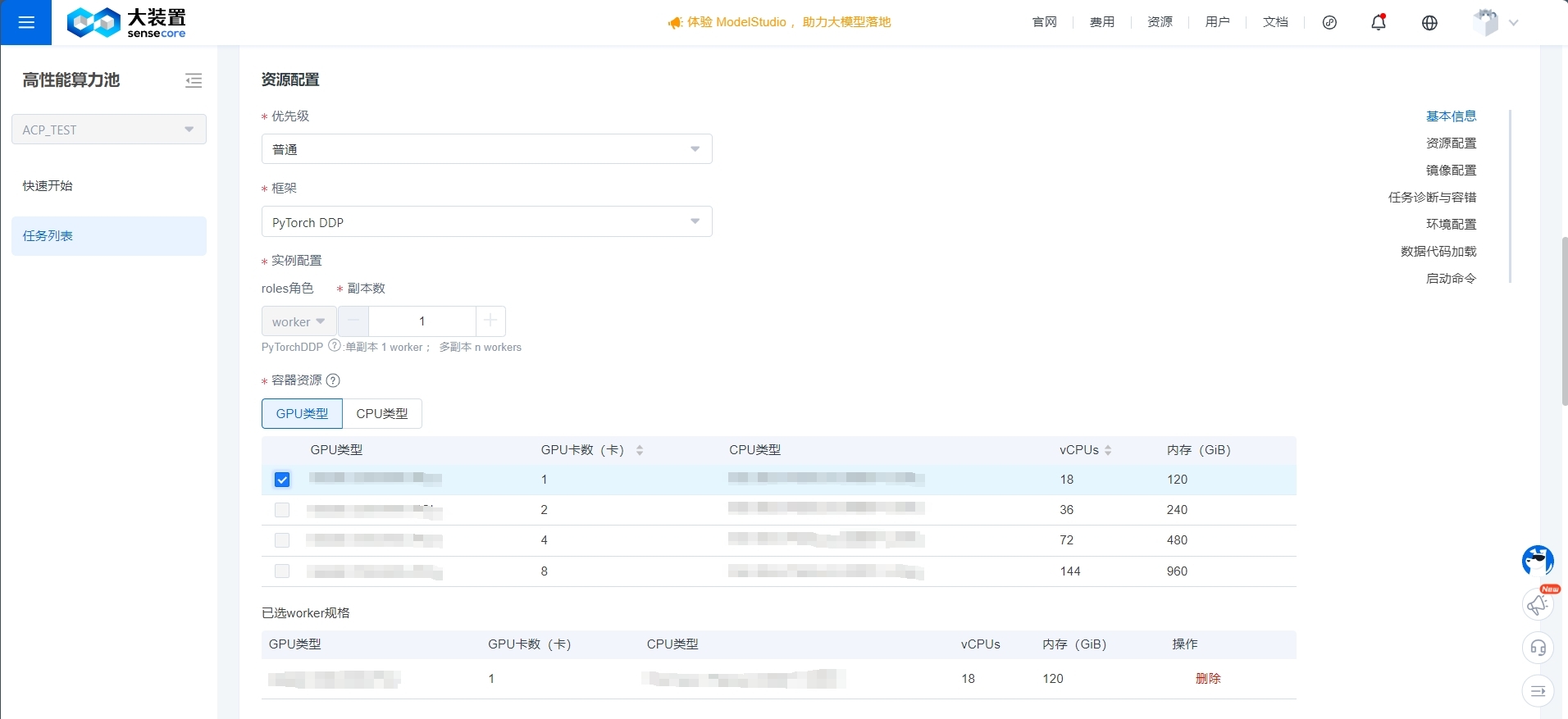
- 优先级:默认工作空间用户只能创建普通优先级的训练任务,工作空间所有者或更高权限的用户,可以配置训练任务优先级为高优、最高;当有高优先级任务待调度时,会阻塞未调度的低优先级任务资源供给,同优先级的训练任务,系统会多维度计算资源的分配进行调度。
- 上面提到的优先级逻辑适用于标准资源和闲时资源,覆盖只有标准资源或者只有闲时资源的场景;
- 当用户同时调度标准资源和闲时资源时,标准资源提交的低优先级任务调度优先级高于闲时资源提交的高优先级任务;
- 标准资源提交的任务已调度不会被高优任务抢占,但是闲时资源提交的任务可以设置被抢占;
- 闲时资源提交的任意优先级的任务不会被(调度失败的)任意优先级的标准任务或空闲任务阻塞;
- 标准任务之间,不同优先级任务不会抢占;
- 高优先级的闲时任务可以抢占低优先级的闲时任务。
- 框架:训练框架和分布式架构做了组合,整合了几种常见的组合:PyTorch DDP、TensorFlow PS、SenseParrots(国产化)和MPI。其中MPI是一种启动方式,在ACP训练池上支持用户在平台上发起 MPI 的分布式训练任务;
- 实例配置:训练为单机训练还是多机训练,通过实例的副本数来决定,目前不支持自定义roles角色。其中,实例是Job的概念,副本是worker的概念(底层是容器pod),多副本即多个worker。一个worker(容器pod)可以支持分配多张GPU卡,也可以绑定整个GPU服务器Node节点。以PyTorch DDP为例,1个副本=1个worker,选择N个(N>1)副本时,将创建一个master和N-1个worker;另外,如果用户需要创建128台8卡H800的作业(Job),副本数(worker)为128,每个副本选择8卡的容器资源(GPU资源)。
- 容器资源:配置单容器的资源类型,此模块会根据选择的集群资源,展示可配置资源类型。

镜像配置
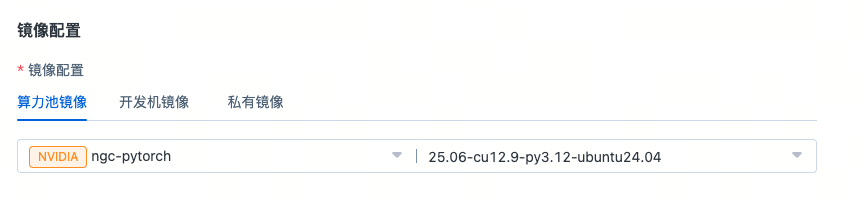
- 算力池镜像:可以选择内置在算力池的官方镜像;图上打上NVIDIA标签的镜像为NVIDIA官方NGC镜像,图中tag表示的含义:25.06对应 PyTorch Release 25.06,并且分别交代了cuda、python和ubuntu24.04的版本信息,更多详情参考NVIDIA官方pytorch-release-notes信息。
- 开发机镜像:可以选择内置在AI开发机上的官方镜像;
- 私有镜像:可以在容器镜像服务中上传用户个人镜像,若需上传个人私有镜像需购买容器镜像服务CCR并上传镜像到SenseCore中。
容错与诊断
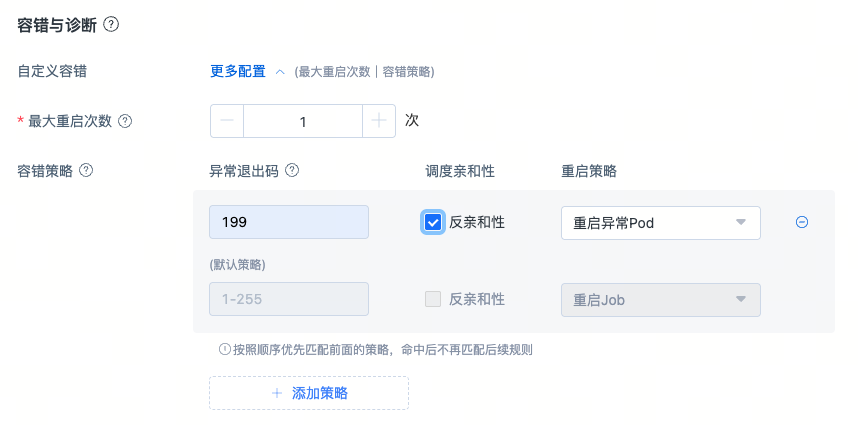
平台开放了自定义容错能力,支持设置最大重启次数以及容错策略(自定义异常错误码),提升平台整体训练的稳定性与效率,延长有效训练时间,更多介绍参考容错与诊断。
- 自动重试:平台在检测到环境异常或节点故障时,能够自动重启任务(Job)或异常 Pod,尝试恢复任务执行。此外,用户还可通过自定义异常退出码,实现更灵活的异常重试控制策略。
1)【最大重启次数】取值范围:-1~99,任务尝试做恢复重启;
2)设置为0值,任务不做恢复重启;平台不具备自动容错能力; 3)如果设置为-1,任务会一直尝试重启;
4)【最大重启次数】为非0的时候,容错策略才有价值,否则属于无效配置。 - 容错策略:支持用户自定义异常退出码,根据自定义的退出码执行相应的容错动作,同时支持设置反亲和调度,将节点标记为异常,重启时避免调度到异常节点上。
1)【异常退出码】:控制pod异常退出时对任务的处理行为,取值范围:1-255 ,支持填"1"、"200-205"、"199,255"、"199,200-204,230"等几类格式;
2)【调度亲和性】:分为反亲和性和亲和性,勾选上反亲和性后,支持对异常节点打标记,任务重试时后不再调度到被标记的异常节点上;
3)【重启策略】:分为重启Job、重启异常Pod和Job失败不再重启。重启Job,任务维度每个pod都需要重启,千卡场景下所有pod重启,初始化时间消耗比较长,预估30分钟;重启异常Pod,只会重启异常的pod,其他pod稳定运行;Job失败不再重启,某些场景下遇到后不希望平台进行重启而是直接退出;
4)容错策略执行规则:没有添加容错策略情况下,平台会按照默认策略来执行。平台按照顺序执行容错策略,从上到下匹配,检测到用户脚本/代码返回异常退出码后,命中后就不再匹配后续的规则。
数据代码加载
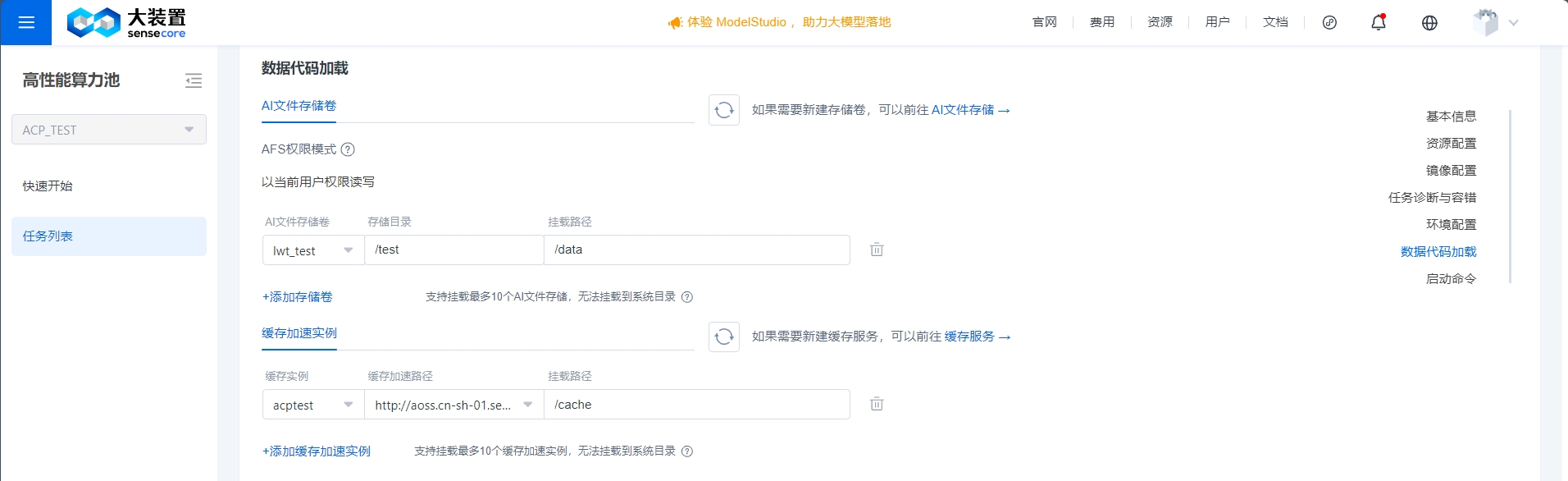
AFS文件存储卷配置:训练代码或者数据集可放在文件存储AFS中,填写要求如下:
- AFS权限模式:由租户管理员管理,应用重新启动后可能出现权限变动。如需root权限读写,请联系租户管理员修改Posix映射管理配置;
- AI文件存储卷:支持选择用户在AFS内用相文件存储卷,若无相关实例需到AFS上创建;
- 存储目录:a)用户可自行填写,若填写需要自行校验挂载目录是否可读写,在AFS-目录管理中查看用户相关权限下的目录;b)默认不选择时,挂载文件存储卷下所有目录;
- 挂载路径:a)若有指定目录由用户确保目录路径;b)若无可填写任意路径,后端会自行创建。
环境配置

- 自定义环境变量:可自主配置运行环境变量,支持最多20个环境变量,无法自定义系统环境变量。
- 节点间SSH免密登录:用于生成节点间SSH免密登录配置,向容器中添加SSH免密登录所需的配置,以便容器之间建立SSH连接。
注意,免密互信文件目录默认为/sensecore/compute/platform/ssh/ssh_config,该目录Pod内为只读权限(商汤sensecore维护),无法编辑,用户可将目录内的文件复制到其他位置进行编辑。

TensorBoard配置

- TensorBoard配置:
开启采集TensorBoard日志:a)为了保证训练结果中输出TensorBoard文件,在编写训练脚本时,您需要在脚本中添加收集TensorBoard相关代码;详看TensorBoard官方; b)配置路径需要与代码中的Tensorboard日志路径保持一致;c)且日志需要写入在文件存储AFS中,即需填写【数据代码加载】配置路径。