功能说明
GPU 的故障率相对较高,单卡日故障率可达万分之五。随着深度学习的广泛应用及模型、数据规模的持续增长,训练任务越来越依赖分布式运行方式,而分布式系统本身也进一步提升了训练异常发生的概率。
大模型训练通常依赖平台提供的能力(如故障节点的自动发现与替换),以增强训练任务的容错性,从而提升整体训练的稳定性与效率,延长有效训练时间。
目前,平台开放了自定义容错能力,支持设置最大重启次数以及容错策略(自定义异常错误码),任务出现训练异常、Python进程hang住、网络通信异常、GPU硬件故障等环境问题时,通过用户脚本或者模型代码控制任务重启。
同时我们平台提供了多种环境(GPU检测、文件存储读写检测、多机多卡间通信检测等)诊断的最佳实践,方便用户根据实际场景提升平台的容错能力,提升实际任务训练的稳定性和效率。
自动重试
平台在检测到环境异常或节点故障时,能够自动重启任务(Job)或异常 Pod,尝试恢复任务执行。此外,用户还可通过自定义异常退出码,实现更灵活的异常重试控制策略。
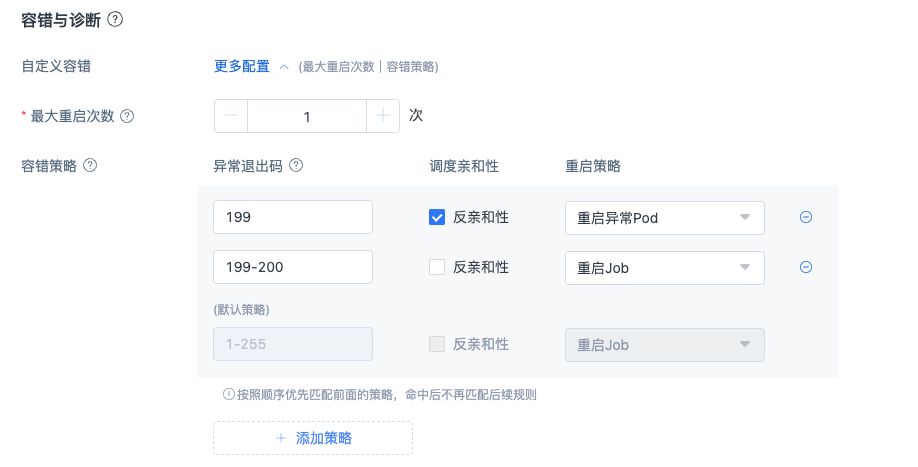
1、【最大重启次数】取值范围:-1~99,任务尝试做恢复重启。
2、设置为0值,任务不做恢复重启;平台不具备自动容错能力。
3、如果设置为-1,任务会一直尝试重启。
4、【最大重启次数】为非0的时候,容错策略才有价值,否则属于无效配置。
容错策略
支持用户自定义异常退出码,根据自定义的退出码执行相应的容错动作,同时支持设置反亲和调度,将节点标记为异常,重启时避免调度到异常节点上。
1、【异常退出码】:控制pod异常退出时对任务的处理行为,取值范围:1-255 ,支持填"1"、"200-205"、"199,255"、"199,200-204,230"等几类格式。
2、【调度亲和性】:分为反亲和性和亲和性,勾选上反亲和性后,支持对异常节点打标记,任务重试时后不再调度到被标记的异常节点上。
3、【重启策略】:分为重启Job、重启异常Pod和Job失败不再重启。重启Job,任务维度每个pod都需要重启,千卡场景下所有pod重启,初始化时间消耗比较长,预估30分钟;重启异常Pod,只会重启异常的pod,其他pod稳定运行;Job失败不再重启,某些场景下遇到后不希望平台进行重启而是直接退出。
4、容错策略执行规则:没有添加容错策略情况下,平台会按照默认策略来执行。平台按照顺序执行容错策略,从上到下匹配,检测到用户脚本/代码返回异常退出码后,命中后就不再匹配后续的规则。
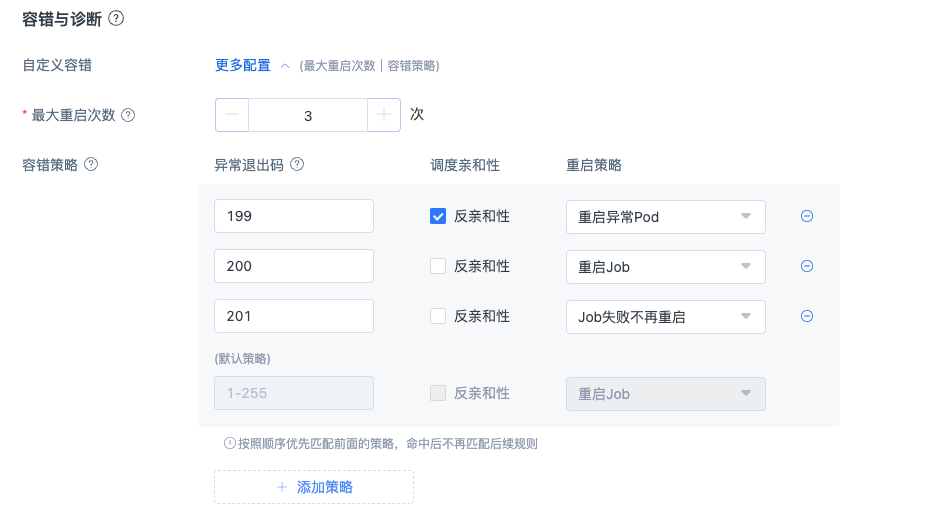
上述容错策略样例解读:
| 异常退出码 | 调度亲和性 | 重启策略 | 容错策略说明 |
| 199 | 反亲和性 | 重启异常Pod | 当检测到用户脚本/代码返回退出码199时,以该退出码退出POD后,打上反亲和标签,平台尝试重启 该异常POD 时,会调度到其他空闲节点上,并且尝试重启 |
| 200 | 亲和性 | 重启Job | 当检测到用户脚本/代码返回退出码为200时,退出所有的POD,任务维度发生重启,重启的时候依然有概率调度到原来异常的节点上 |
| 201 | 亲和性 | Job失败不再重启 | 当检测到用户脚本/代码返回退出码为201时,以该退出码直接退出POD,平台不再尝试重启 |
| 1-255(默认策略) | 亲和性 | 重启Job | 当检测到用户脚本/代码返回退出码为非199、200和201时,但是在1-255范围内,会执行默认策略,平台会尝试重启job,每次重启都有可能调度在原来的异常节点上。 |
注意:多个退出码的总重启次数不超过平台的【最大重启次数】。
当出现如下场景时,检测到日志打印出199退出码时,命中容错策略,按照【重启异常POD】和【反亲和性】规则来执行,异常POD会被重启一次,且会调度到其他节点上,命中后不再匹配后续的容错规则。