常用检测方式(用户手册)
1 常见问题
GPU异常
- nvidia-smi中发现GPU设备异常
- 训练代码的日志中有CUDA相关的报错
- dmesg中出现XID相关的错误日志
网络异常
- 训练代码的日志中有NCCL或NCCL相关的报错
- 从远端下载或读取数据出现异常
AFS读写异常
- 训练代码中出现读写AFS数据相关的异常
2 检测方案说明
关于环境检测,目前提供GPU硬件检测、网络通信检测以及存储IO检测,环境的诊断可以发生在任务运行前和任务失败后2个时机。
- 训练任务开始前的 预热检测 ,以保证任务开始时的环境正常。
a. python代码示例checker_warmup.py
from check_disk import check_disk # reference test solution examples
from check_gpu import check_gpu # reference test solution examples
from training_task import training_task # user training code
import sys
def run_warmup_checks():
if check_disk("/data") and check_gpu():
return True
return False
# Warmup check
if __name__ == "__main__":
if not run_warmup_checks():
print("Check failed, exiting with code 199.")
sys.exit(199)
# Training code here
training_task ()
注意:training_task 是用户的训练代码。
b. 启动命令示例
set -e
python checker_warmup.py || exit 199
# user’s command
python training_task.py
- 训练任务失败后的 失败检测 ,以确定失败节点上是否有环境问题,以及重试后是否允许再次调度到该失败节点上。
a. python代码示例(失败后调用的检测):checker_fail.py
import subprocess
import sys
import os
from training_task import training_task # user training code
def run_script(script_name, *args):
try:
result = subprocess.run(["python", script_name, *args], check=True)
return result.returncode == 0
except subprocess.CalledProcessError as e:
print(f"[ERROR] 脚本 {script_name} 执行失败,返回码:{e.returncode}")
return False
except Exception as e:
print(f"[ERROR] 执行脚本 {script_name} 时出现异常:{e}")
return False
def run_fail_checks():
# 建议使用绝对路径进行脚本调用,以规避脚本运行时所在路径的干扰
CHECKER_SCRIPT_PREFIX = "/data/"
disk_script = os.path.join(CHECKER_SCRIPT_PREFIX, "check_disk.py") # reference test solution examples
gpu_script = os.path.join(CHECKER_SCRIPT_PREFIX, "check_gpu.py") # reference test solution examples
nccl_script = os.path.join(CHECKER_SCRIPT_PREFIX, "check_nccl_simple.py") # reference test solution examples
# 使用不同进程对CUDA进行初始化,避免 check_gpu 和 check_nccl_simple 的重复初始化导致CUDA调用失败
disk_ok = run_script(disk_script, "/data")
gpu_ok = run_script(gpu_script)
nccl_ok = run_script(nccl_script)
return disk_ok and gpu_ok and nccl_ok
# Training code here
training_task()
# Training failed check
# If user need to begin check
if __name__ == "__main__":
need_to_check = True
if need_to_check and not run_fail_checks():
print("Check failed, exiting with code 199.")
sys.exit(199)
b. 启动命令示例(需要将检测项封装成可执行脚本)
set -e
# warmup check
python checker_warmup.py || exit 199
# run training command
# if failed,run check
python training_task.py || python checker_fail.py || exit 199
- 检测未通过情况下,可以配合平台容错能力一起使用,提升GPU资源使用效率,和提高有效训练时间。
添加异常退出码199,勾选反亲和性,重启策略设置为重启异常Pod,以及最大重启次数为3。当环境检测不通过时,可以尝试重启异常pod,并且调度到新的一个节点上,当然非硬件故障,也可以只是重启,不换节点。
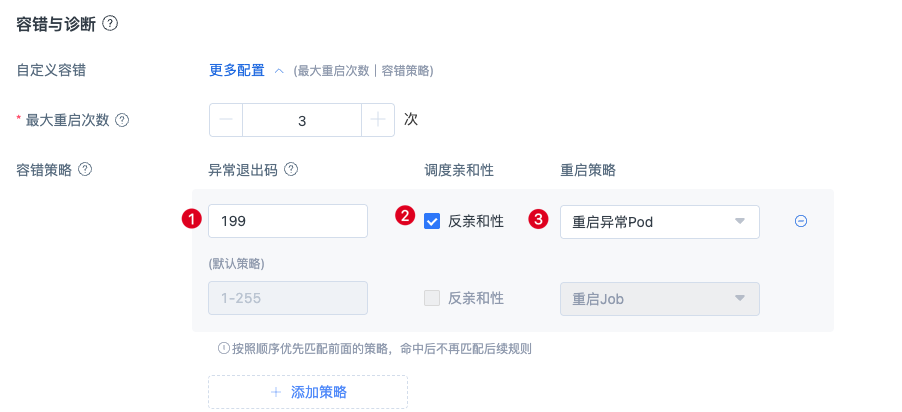
3 环境检测示例
GPU检测
- pytorch在指定GPU上跑矩阵乘法,示例代码
check_gpu.py如下:
import torch
import sys
def list_available_gpus():
if not torch.cuda.is_available():
print("没有可用的GPU!")
return 0
gpu_count = torch.cuda.device_count()
print(f"系统中共有 {gpu_count} 个GPU:")
for i in range(gpu_count):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
return gpu_count
# 指定gpu_id进行测试
def check_gpu_matmul(gpu_id=0, matrix_size=2048, test_rounds=5):
# 检查是否有可用的 GPU
if not torch.cuda.is_available():
print("CUDA GPU 不可用")
return
device = torch.device(f'cuda:{gpu_id}')
print(f"使用设备: {torch.cuda.get_device_name(device)}")
print(f"矩阵大小: {matrix_size}x{matrix_size}, 测试轮数: {test_rounds}")
# 创建两个大矩阵,值全为 1,放在 GPU 上
A = torch.ones((matrix_size, matrix_size), device=device)
B = torch.ones((matrix_size, matrix_size), device=device)
expected = torch.full((matrix_size, matrix_size), float(matrix_size), device=device)
total_time = 0
success = True
for round in range(test_rounds):
# 记录开始时间
start_time = torch.cuda.Event(enable_timing=True)
end_time = torch.cuda.Event(enable_timing=True)
start_time.record()
# 执行矩阵乘法
C = torch.matmul(A, B)
end_time.record()
# 等待GPU操作完成
torch.cuda.synchronize()
# 计算耗时(毫秒)
elapsed_time = start_time.elapsed_time(end_time)
total_time += elapsed_time
# 验证结果
if not torch.allclose(C, expected, atol=1e-3):
success = False
print(f'第 {round + 1} 轮测试失败,GPU {gpu_id} 可能有问题')
break
print(f'第 {round + 1} 轮测试完成,耗时: {elapsed_time:.2f} ms')
if success:
avg_time = total_time / test_rounds
print(f'\nGPU {gpu_id} 所有测试通过!')
print(f'平均每轮耗时: {avg_time:.2f} ms')
return True
else:
print(f'\nGPU {gpu_id} 测试失败!')
return False
def check_gpu():
print("\n开始对GPU进行测试...")
gpu_count = list_available_gpus()
ret = True
if gpu_count > 0:
print("\n开始测试所有GPU的矩阵乘法...")
# 遍历测试所有GPU
for gpu_id in range(gpu_count):
if not check_gpu_matmul(gpu_id=gpu_id):
ret = False
print("-" * 50)
return ret
if __name__ == "__main__":
success = check_gpu()
sys.exit(0 if success else 1)
- 开源的GPU-BURN覆盖的检测方式更加完备,可以使用该方式进行测试
a. GPU-BURN需要进行编译,或使用指定的官方镜像,或在自带GPU-BURN二进制文件的镜像作为base制作新的镜像
网络检测
- 可以尝试使用torch检测单机网络通信情况,示例代码
check_nccl_simple.py如下:
import torch
import torch.distributed as dist
import os
import sys
from multiprocessing import Process
# 设置分布式通信环境(NCCL后端)
def setup(rank, world_size):
master_addr = os.getenv("MASTER_ADDR", "127.0.0.1") # 如果环境变量不存在,使用默认值
master_port = os.getenv("MASTER_PORT", "29500")
# 设置环境变量供进程间通信使用
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
# 初始化 NCCL 后端的进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 设置当前进程使用的 GPU 设备
torch.cuda.set_device(rank)
# 清理分布式环境
def cleanup():
dist.destroy_process_group()
# 每个进程运行的主函数
def run(rank, world_size):
setup(rank, world_size)
tensor = torch.ones(1).cuda(rank) * (rank + 1)
print(f"[Rank {rank}] Before AllReduce: {tensor.item()}")
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"[Rank {rank}] After AllReduce: {tensor.item()}")
cleanup()
# 封装的 NCCL 简单测试函数
def check_nccl_simple():
print("\n开始对单机nccl网络进行测试...")
try:
world_size = torch.cuda.device_count()
if world_size < 1:
print("No CUDA devices available")
return False
# 手动管理多进程方式启动所有 GPU 参与 NCCL 测试
processes = []
for rank in range(world_size):
p = Process(target=run, args=(rank, world_size))
p.start()
processes.append(p)
for p in processes:
p.join()
print("NCCL test completed")
return True
except Exception as e:
print(f"NCCL test failed with error: {e}")
return False
if __name__ == "__main__":
success = check_nccl_simple()
print(f"NCCL test {'succeeded' if success else 'failed'}")
sys.exit(0 if success else 1)
多见检测方案参考附录:集群检测的注意事项
可以使用厂商对应的通信库测试工具,如NVIDIA的NCCL-TEST,以获取更加完备的检测效果
a. NCCL-TEST需要进行编译,或使用指定的官方镜像,或在自带NCCL-TEST二进制文件的镜像作为base制作新的镜像
文件目录IO检测
- 可以进行对指定的文件目录写入读取的测试,示例代码
check_disk.py如下:
import os
import time
import random
import socket
import sys
from datetime import datetime
"""检测磁盘读写
Paramters:
directory: 指定进行测试的目录
Returns:
bool: 检测通过即为True,检测失败即为False
"""
def check_disk(directory):
print(f'\n开始对目录{directory}进行读写测试...')
"""在指定目录执行1GB数据的读写测试"""
if not os.path.exists(directory):
print(f'错误: 目录不存在 {directory}')
return False
if not os.access(directory, os.W_OK):
print(f'错误: 目录无写入权限 {directory}')
return False
hostname = socket.gethostname()
timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
filename = f"io-test-file-{hostname}-{timestamp}"
test_file = os.path.join(directory, filename)
file_size = 1024 * 1024 * 1024 # 1GB
block_size = 1024 * 1024 # 1MB
blocks = file_size // block_size
try:
# 写入测试
print(f'\n开始写入测试 {directory}')
write_start = time.time()
with open(test_file, 'wb') as f:
for _ in range(blocks):
data = random.randbytes(block_size)
f.write(data)
write_time = time.time() - write_start
write_speed = file_size / write_time / (1024 * 1024) # MB/s
print(f'写入完成: {write_speed:.2f} MB/s')
# 读取测试
print('\n开始读取测试')
read_start = time.time()
with open(test_file, 'rb') as f:
while True:
data = f.read(block_size)
if not data:
break
read_time = time.time() - read_start
read_speed = file_size / read_time / (1024 * 1024) # MB/s
print(f'读取完成: {read_speed:.2f} MB/s')
# 清理测试文件
os.remove(test_file)
return True
except Exception as e:
print(f'IO测试出错: {e}')
if os.path.exists(test_file):
try:
os.remove(test_file)
except:
pass
return False
if __name__ == "__main__":
if len(sys.argv) != 2:
print("用法: python check_disk.py <directory>")
sys.exit(1)
directory = sys.argv[1]
success = check_disk(directory)
sys.exit(0 if success else 1)
4 集群检测
在分布式任务失败时进行集群检测,需要确认所有节点上的任务进程都已经退出,处于待检测状态,否则检测结果可能会收到残余负载的影响产生波动。
对于MPI任务来说,mpi launcher退出时所有的远程进程均已退出,可以直接执行检测。
对于PyTorch DDP任务,需要在节点之间同步训练脚本的运行状态,但是 torchrun 启动的任务只有在启用 c10d 会合后端且开启重试时,才会将任务失败事件广播到其他节点以触发全局重试。关于各种会合后端的配置,详见 https://docs.pytorch.org/docs/stable/elastic/run.html 。
如果不是以上配置,可能会出现部分节点失败,但其他节点卡住等待集合通信并在很长时间后才失败。这种情况下,从失败节点直接发起集群检测可能会受到仍在运行的其他节点上训练进程的干扰。此时需要在训练代码中自行实现相关的watchdog逻辑,一个进程失败时触发所有训练进程的主动退出。这可以通过使用 torch.distributed.TCPStore 作为节点之间的沟通工具来实现,以下是一个简单的watchdog例子,需要整合到训练代码中:
from datetime import timedelta
import _thread
import os
import threading
from functools import wraps
import torch.distributed as dist
# the decorator factory class for ease of use.
# job_id must be a unique string, known to ALL workers.
# defaults to the rendezvous run_id (by env TORCHELASTIC_RUN_ID).
def trapped(main_train_loop):
@wraps(main_train_loop)
def run_with_trap(*args, **kwargs):
# reuse the info provided by torchrun.
master_addr = os.environ.get("MASTER_ADDR", "localhost")
master_port = int(os.environ.get("MASTER_PORT", "23456"))
world_size = int(os.environ.get("WORLD_SIZE", "1"))
rank = int(os.environ.get("RANK", "0"))
def create_tcp_store(timeout=timedelta(seconds=15)):
try:
return dist.TCPStore(
master_addr,
master_port,
world_size=world_size,
is_master=(rank == 0),
timeout=timeout,
)
except Exception:
if rank != 0:
raise
# retry in case the store is inited by torchrun.
# the port will be occpuied by the store server.
# in this case try reconnect as client.
return dist.TCPStore(
master_addr,
master_port,
world_size=world_size,
is_master=False,
timeout=timeout,
)
store = create_tcp_store()
# required to make a unique prefix so things are separated.
job_id = os.environ["TORCHELASTIC_RUN_ID"]
# use a unique key to init the indicator for this new run, only by rank 0.
ffw_key = f"/sensecore/lepton/deepscale/trap/job/{job_id}/first_failed_worker"
ffw_value_none = "none"
if rank == 0:
store.set(ffw_key, ffw_value_none)
# barrier for all workers, the value is not important,
# just to ensure everybody reads the same restart_count as rank 0.
ffw_value = store.get(ffw_key).decode()
print(f"[{rank=}] initial {ffw_value=}")
done_watch = threading.Event()
def poll_workers():
try:
while not done_watch.wait(3):
ffw_value = store.get(ffw_key).decode()
if ffw_value != ffw_value_none:
print(
f"[{rank=}] interrupt because observed failed worker: {ffw_key}={ffw_value}"
)
return
print(f"[{rank=}] {ffw_value=}")
finally:
if not done_watch.is_set():
# always exit the whole process if this thread ends.
_thread.interrupt_main()
# or just os._exit(1) to forcifully shutdown without clean.
# launch a thread to watch first failed worker.
w = threading.Thread(None, poll_workers, daemon=True)
w.start()
try:
# run the original function.
return main_train_loop(*args, **kwargs)
except Exception as e:
# update with compare-and-set, so it is updated only when the original value is "none".
# if use plain set(), the value would be last failed worker rather than first.
print(f"[{rank=}] mark me fail because exception: {e}")
store.compare_set(ffw_key, ffw_value_none, str(rank))
# re-raise to original caller.
raise
finally:
# close the watching thread.
done_watch.set()
w.join()
return run_with_trap
if __name__ == "__main__":
# usage: decorate on the training loop
@trapped
def hello():
print("hello!")
raise ValueError("hello failed!")
hello()
TCPStore的使用详见官方文档。
5 常用开源工具
以下列举了一些常用的开源工具及其使用方式
GPU-BURN
源码仓库:https://github.com/wilicc/gpu-burn
安装
使用自带可执行二进制文件的镜像,如官方镜像:
ubuntu22.04-pytorch2.1.0-py310-cuda12.2:0630,文件所在目录为:/sensecore/acp/bin使用源码编译
mkdir -p /opt/checker
cd /opt/checker
git clone https://github.com/wilicc/gpu-burn
cd gpu-burn
make
# 设置环境变量
export GPUBURN_DIR="/opt/checker/gpu-burn"
使用
已有gpu-burn二进制文件的情况下,可以使用该文件进行测试,示例脚本:run-gpu-burn.sh
#!/bin/bash
# 可根据环境变量进行修改
# 默认值/sensecore/acp/bin,为商汤大装置官方镜像ubuntu22.04-pytorch2.1.0-py310-cuda12.2:0630的gpu-burn二进制文件路径
home=${GPUBURN_DIR:-"/sensecore/acp/bin"}
gpuburn_bin="${home}/gpu_burn"
if [ -f $gpuburn_bin ]; then
cd $home
$gpuburn_bin -d 5
if [ "$?" == "0" ]; then
exit 0
fi
fi
exit 1